도입
"AI 캐릭터와 대화한다"는 문장은 간단해 보이지만, 사용자가 기대하는 경험은 하나가 아니다. 드라마에 참여하듯 플롯을 따라가고 싶은 사람, 특정 주제로 이야기를 나누고 싶은 사람, 그리고 캐릭터 자체와 관계를 쌓고 싶은 사람 — 이 세 가지 욕구는 근본적으로 다르다.
Plit은 이 세 가지를 각각 스토리 모드(감독형 AI), 토크룸 모드(목적형 AI), **캐릭터 챗 모드(관계형 AI)**로 분리했다. 하나의 채팅 UI 뒤에 하나의 AI 파이프라인이 있지만, 모드에 따라 프롬프트 구성, 메모리 전략, 상태 관리가 전혀 달라진다.
같은 캐릭터 "Emily Johnson"이 스토리에서는 로맨스 상대역을, 토크룸에서는 영어회화 튜터를, 캐릭터 챗에서는 "나만의 AI 친구"를 맡는다. 캐릭터의 성격과 말투는 동일하지만, 대화의 목적과 구조가 완전히 다르다.
이 글에서는 3모드 아키텍처의 설계 결정과 실제 구현을 기록한다. 캐릭터 독립 엔티티 설계, 모드별 프롬프트 빌더 분기, 메모리 전략 차이를 중심으로 다룬다.
핵심 1: 캐릭터 독립 엔티티 설계
3모드 아키텍처의 전제는 캐릭터가 특정 모드에 종속되지 않는다는 것이다. "한시우"라는 캐릭터는 스토리 A, 스토리 B(시즌 2), 토크룸 C에 동시에 참조될 수 있다. 캐릭터 자체가 IP다.
이를 위해 캐릭터 원본 데이터와 모드별 맥락을 명확히 분리했다.
// schema.prisma — 캐릭터 독립 엔티티
model Character {
id String @id @default(uuid())
name String
persona Json? // { personality, speaking_style, speech_examples[] ... }
identity Json? // { backstory, core_traits[], motivation, flaw, archetype }
emotionConfig Json? @map("emotion_config")
safety Json? // { never_do[], always_do[], escalation_response }
// N:M 연결 — 어떤 모드에서든 참조 가능
storyLinks StoryCharacter[]
talkRoomLinks TalkRoomCharacter[]
@@map("characters")
}
핵심은 N:M 연결 테이블이다. 캐릭터의 원본(페르소나, 말투, 감정 체계)은 characters 테이블에 있고, 모드별 맥락은 연결 테이블이 담당한다.
// 스토리-캐릭터 연결 — 이 스토리에서의 역할/호감도/관계
model StoryCharacter {
id String @id @default(uuid())
storyId String @map("story_id")
characterId String @map("character_id")
role CharacterRole // MAIN_LOVE, RIVAL, FRIEND...
initialAffinity Int @default(15) @map("initial_affinity")
storyContext Json? @map("story_context") // { secret, arc, relationships[] }
affinityThresholds Json? @map("affinity_thresholds") // { cold, wary, neutral, warm, intimate }
@@unique([storyId, characterId])
@@map("story_characters")
}
// 토크룸-캐릭터 연결 — 이 방에서의 인사말/대화 설정
model TalkRoomCharacter {
id String @id @default(uuid())
roomId String @map("room_id")
characterId String @map("character_id")
greetingMessage String? @map("greeting_message") @db.Text
roomContext String? @map("room_context") @db.Text
responseLength ResponseLength @default(MEDIUM)
@@unique([roomId, characterId])
@@map("talk_room_characters")
}
같은 캐릭터가 스토리에서는 MAIN_LOVE 역할에 초기 호감도 15, storyContext.secret에 비밀을 품고, 토크룸에서는 영어 튜터로 "Hi! Ready to practice English?"라는 인사말을 갖는다. 캐릭터의 본질(성격, 말투)은 동일하되, 맥락만 달라지는 구조다.
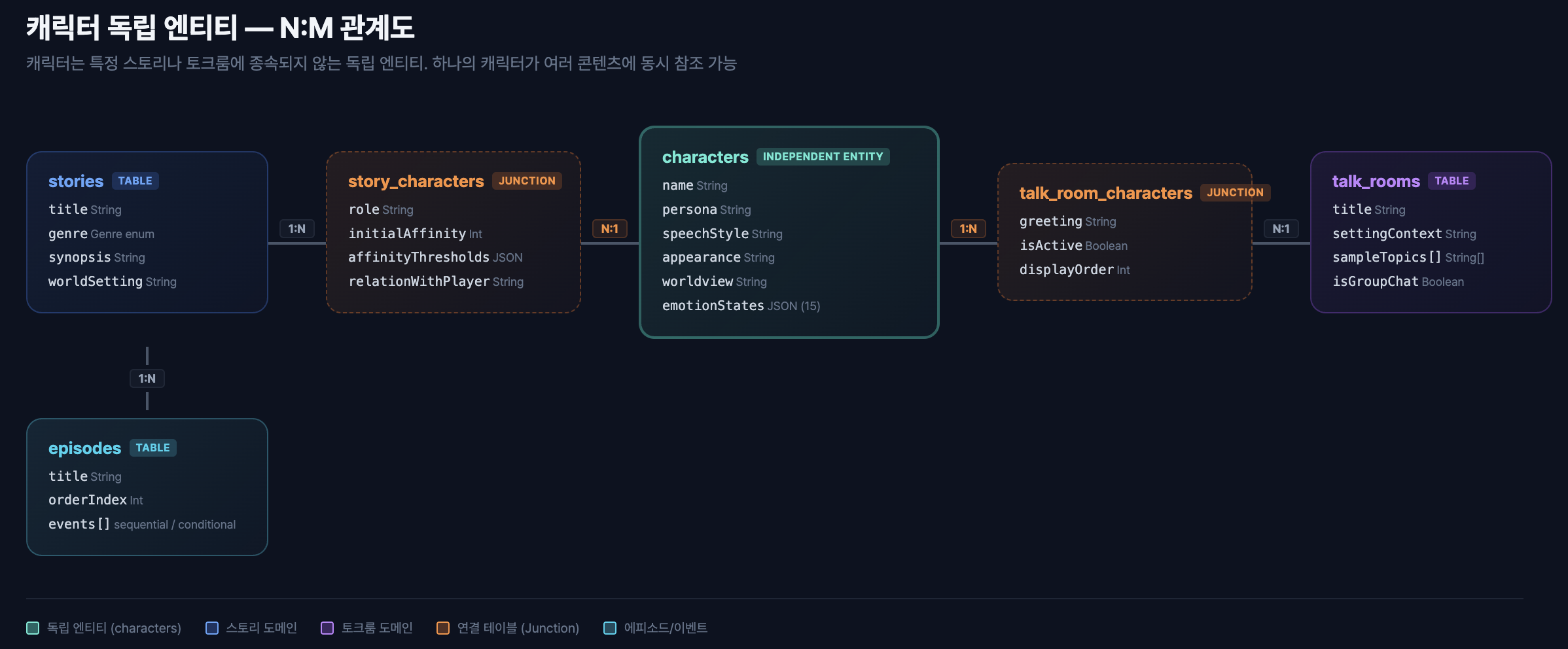
이 설계의 실질적 이점은 콘텐츠 확장성이다. 시즌 2를 만들 때 같은 characterId로 새 StoryCharacter를 연결하면 된다. 크리에이터가 인기 캐릭터를 자기 토크룸에 배정할 때도 TalkRoomCharacter만 추가하면 된다.
핵심 2: 스토리 모드 — 감독형 AI
스토리 모드의 중심축은 플롯이다. 에피소드와 이벤트로 구조화된 서사 안에서 AI가 감독 역할을 수행한다.
구조는 Story > Episode > Event의 3단 계층이다. 에피소드는 연속 대화 흐름이고, 이벤트는 그 흐름 속에서 조건 충족 시 삽입되는 특별 장면이다. 이벤트에는 두 가지 트리거 유형이 있다.
| trigger_type | 설명 | 예시 |
|---|---|---|
sequential | 메시지 수 도달 시 무조건 진행 | "10번째 메시지 이후 자기소개 시간" |
conditional | 호감도/키워드/플래그 조건 충족 시 | "호감도 50 이상이면 옥상 대화" |
스토리 전용 시스템으로 **호감도(Affinity)**가 있다. 캐릭터별 0~100 수치로, 대화에서 +-5, 이벤트에서 +-20 범위로 변동한다. 호감도에 따라 캐릭터의 말투와 태도가 달라지며, 스토리 분기의 핵심 조건이 된다. StoryCharacter.affinityThresholds에 구간별 태도가 정의되어 있다.
cold(0~19): 경계, 짧은 대답, 눈을 마주치지 않음
wary(20~39): 의심 속 호기심, 간헐적 대화
neutral(40~59): 편안한 대화, 가끔 먼저 말을 걸기도
warm(60~79): 장난, 신체 접촉, 질투 반응
intimate(80~100): 고백, 비밀 공유, 독점적 감정
메모리는 에피소드 범위, 최대 8개다. 에피소드 전환 시 리셋된다. 메모리에는 호감도 스냅샷이 포함되어 "그때 호감도가 몇이었는지"도 기억한다.
핵심 3: 토크룸 모드 — 목적형 AI
토크룸의 중심축은 방 테마다. settingContext(상황 설정)와 sampleTopics(추천 화제)가 대화의 방향을 정의하고, 캐릭터는 그 테마에 배정된 출연자다.
스토리와의 결정적 차이:
- 에피소드도 이벤트도 없다. 플롯 진행이 아니라 자유 대화다.
- 호감도 시스템이 없다. 분기나 태도 변화의 기준이 테마 준수다.
- 캐릭터 교체가 가능하다. "영어회화 튜터" 방에서 Emily를 다른 캐릭터로 바꿔도 방의 목적(영어 회화 연습)은 유지된다.
- 그룹 채팅을 지원한다. 여러 AI 캐릭터를 한 방에 초대할 수 있다.
메모리는 방 범위, 최대 12개다. 스토리보다 4개 더 많은 이유는 토크룸이 장기적 관계를 지향하기 때문이다. 에피소드 전환으로 리셋되는 스토리와 달리, 토크룸 메모리는 방 삭제 전까지 지속된다. 크로스 세션으로 "지난번에 우리가 나눈 이야기"를 기억한다.
핵심 4: 프롬프트 빌더 분기
3모드 아키텍처의 핵심 구현은 PromptBuilder에 있다. 하나의 클래스가 isTalk 플래그에 따라 완전히 다른 시스템 프롬프트를 조립한다.
// prompt-builder.ts — 모드별 프롬프트 조립 분기
build(): string {
this.parts = [];
if (this.input.isTalk) {
this.buildTalkDirectorSection(); // 토크 디렉터 지시문
this.buildPlayerInfoSection();
this.buildCharacterProfilesSection();
this.buildTargetEmphasisSection();
this.buildAffinitySection();
this.buildMemoriesSection();
this.buildUserProfileSection();
this.buildCharacterStatesSection();
this.buildActiveTopicsSection();
this.buildRecentHistorySection();
this.buildTalkOutputFormatSection(); // 토크 전용 출력 포맷
} else {
this.buildDirectorSection(); // 스토리 디렉터 지시문
this.buildPlayerInfoSection();
this.buildSceneContextSection(); // 에피소드/장면 맥락 (스토리 전용)
this.buildCharacterProfilesSection();
this.buildRelationshipSection(); // 캐릭터 간 관계 (스토리 전용)
this.buildSpatialRulesSection(); // 공간/장면 규칙 (스토리 전용)
this.buildTargetEmphasisSection();
this.buildAbsentMentionSection(); // 부재 캐릭터 처리 (스토리 전용)
this.buildAffinitySection();
this.buildMemoriesSection();
this.buildUserProfileSection();
this.buildCharacterStatesSection();
this.buildActiveTopicsSection();
this.buildPlotDirectionsSection(); // 이벤트 상태머신 (스토리 전용)
this.buildRecentHistorySection();
this.buildOutputFormatSection(); // 스토리 전용 출력 포맷
}
return this.parts.join('\n\n');
}
차이가 명확하다. 스토리 전용 섹션 5개(장면 맥락, 관계 규칙, 공간 규칙, 부재 캐릭터, 플롯 디렉션)가 토크에서는 통째로 빠진다. 대신 토크는 자체적인 디렉터와 출력 포맷을 갖는다.
두 디렉터 섹션의 지시문을 비교하면 설계 철학의 차이가 드러난다.
스토리 디렉터 — 서사 진행이 최우선:
// buildDirectorSection() — 스토리 감독형 AI
`너는 ${contentType} 스토리의 작가이다.
유저의 행동에 대한 나레이션과 캐릭터 대사를 생성한다.
[스토리 진행 규칙]
- 에피소드 줄거리 가이드의 주요 이벤트를 자연스럽게 진행시켜라.
- 유저가 줄거리와 무관한 대화를 반복하면,
나레이션으로 다음 이벤트로 부드럽게 유도하라.`
토크 디렉터 — 자유 대화가 최우선:
// buildTalkDirectorSection() — 토크 목적형 AI
`너는 토크 모드의 AI 캐릭터이다.
플레이어와 자연스럽고 몰입감 있는 1:1 대화를 나눠라.
[토크 규칙]
- 시나리오나 이벤트 진행이 없다. 대화 흐름에 따라 자연스럽게 반응하라.
- 일방적으로 질문만 하지 말고, 캐릭터의 생각과 경험도 나눠라.`
출력 포맷도 다르다. 스토리는 narration + dialogue 혼합 응답에 currentEvent(이벤트 상태머신)와 sceneCharacters(장면 내 캐릭터 추적)가 필수다. 토크는 dialogue만 사용하며, 행동 묘사를 대사 텍스트 안 괄호에 포함한다. 나레이션 타입을 아예 사용하지 않는다.
// 스토리 출력 — narration + dialogue + 이벤트 상태
{
"currentEvent": "rooftop_talk",
"sceneCharacters": ["한시우", "이하늘"],
"items": [
{"type": "narration", "text": "옥상 문이 열리며 바람이 불어왔다."},
{"type": "dialogue", "character": "한시우", "text": "...여기까지 올라온 거야?"}
]
}
// 토크 출력 — dialogue만, 행동 묘사는 괄호 안
{
"items": [
{"type": "dialogue", "character": "Emily", "text": "(미소를 지으며) Let's try again!"}
]
}
핵심 5: 메모리 전략 차이
세 모드의 메모리 전략은 "무엇을 기억하고, 얼마나 오래 유지하며, 어디까지 참조하느냐"에서 갈라진다.
| 스토리 | 토크룸 | 캐릭터 챗 (Phase 2) | |
|---|---|---|---|
| 범위 | 에피소드 단위 | 방 단위 | 캐릭터-사용자 쌍 (전체 모드 통합) |
| 최대 개수 | 8개 | 12개 | 관련도 기반 검색, 제한 없음 |
| 리셋 조건 | 에피소드 전환 시 | 방 삭제 시 | 삭제하지 않음 |
| 검색 방식 | recency + vector (에피소드 내) | recency + vector (방 내) | vector (전체 모드 통합) |
| 특수 기능 | 호감도 스냅샷 포함 | 크로스 세션 지속 | 크로스 컨텍스트 참조 |
스토리와 토크의 메모리는 같은 SessionMemory 모델을 사용하지만, 세션 범위가 다르다.
// 스토리와 토크 공용 메모리 모델
model SessionMemory {
id String @id @default(uuid())
sessionId String @map("session_id")
summary String @db.Text
involvedCharacters String[] @map("involved_characters")
affinitySnapshot Json? @map("affinity_snapshot") // 스토리 전용
embedding Unsupported("vector(512)")? // pgvector 시맨틱 검색
keyDetails Json? @map("key_details")
@@map("session_memories")
}
스토리 메모리에만 affinitySnapshot이 채워진다. "그때 한시우 호감도가 45였다"는 정보가 메모리에 포함되어, AI가 과거 관계 상태를 인지한 채 대화할 수 있다.
캐릭터 챗(Phase 2)의 크로스 컨텍스트 메모리는 기존 인프라를 재활용하는 설계다. 새 테이블을 만드는 대신, 검색 시 캐릭터 ID를 기준으로 해당 캐릭터가 참여한 모든 세션의 메모리를 통합 조회한다. 스토리에서 나눈 대화, 토크룸에서 나눈 대화, 캐릭터 챗 자체 대화가 하나의 벡터 검색으로 합쳐진다. "스토리에서 우리 호감도 엄청 올랐었는데"라는 사용자 발화에 대해, 캐릭터가 실제로 스토리 세션의 메모리를 참조해서 반응할 수 있다.

정리
3모드 아키텍처를 설계하면서 확인한 핵심 판단을 정리한다.
-
"같은 챗봇"이 아니다. 대화의 중심축(플롯/테마/캐릭터)이 다르면, 프롬프트 구조·메모리 전략·상태 관리가 완전히 달라져야 한다. 하나의 범용 프롬프트로 세 가지를 커버하려는 시도는 모두를 평범하게 만든다.
-
캐릭터를 독립 엔티티로 설계하라. 캐릭터를 특정 모드에 종속시키면, 크로스 모드 경험이 불가능해지고 콘텐츠 재활용이 막힌다. N:M 연결 테이블로 원본과 맥락을 분리하는 것이 핵심이다.
-
프롬프트 빌더는 조합 패턴이 맞다.
PromptBuilder가 모드별로 섹션을 선택적으로 조립하는 구조 덕분에, 공통 섹션(캐릭터 프로필, 메모리, 대화 기록)은 재사용하면서 모드별 차이(디렉터, 출력 포맷, 플롯 관련 섹션)만 분기할 수 있다. -
메모리 범위가 경험을 결정한다. 에피소드 범위(스토리)는 "이 회차에 집중"을, 방 범위(토크)는 "장기적 관계"를, 크로스 컨텍스트(캐릭터 챗)는 "나를 아는 AI"를 만든다. 같은 RAG 인프라를 쓰더라도 검색 범위의 차이가 사용자 경험의 차이다.
-
출력 포맷을 분리하라. 스토리의
narration+dialogue+currentEvent포맷과 토크의dialogue만 사용하는 포맷은 근본적으로 다르다. 하나의 출력 포맷으로 억지로 통합하면 불필요한 필드와 혼란만 늘어난다. -
확장 포인트를 남겨라.
PromptBuildInput의isTalk플래그 하나로 분기하는 현재 구조는, 캐릭터 챗이 추가될 때isCharacterChat플래그와buildCharacterChatDirectorSection()을 추가하면 된다. 기존 코드를 수정하지 않고 새 모드를 끼워넣을 수 있다.