도입
Plit은 AI 캐릭터와 자연어로 대화하며 스토리를 진행하는 AI 채팅 플랫폼이다. 스토리 모드에서는 여러 캐릭터가 등장하고, 호감도에 따라 말투와 태도가 변하며, 이벤트가 분기한다. 토크룸 모드에서는 테마 기반 1:1/그룹 대화가 이루어진다.
단일 모델 호출로 끝나지 않는다. "누가 대답할지" 결정하고, "어떤 톤과 내용으로 말할지" 생성하고, "호감도와 감정 상태를 어떻게 갱신할지" 평가하는 — 세 단계가 필요하다.
사용자가 메시지 하나를 보내면, 백엔드에서는 Target Resolution → Response Generation → State Update 3단계 파이프라인이 실행된다. 이 글에서는 이 파이프라인의 구조와 스트리밍 처리 방식을 실제 코드 기반으로 기록한다.
아키텍처 개요
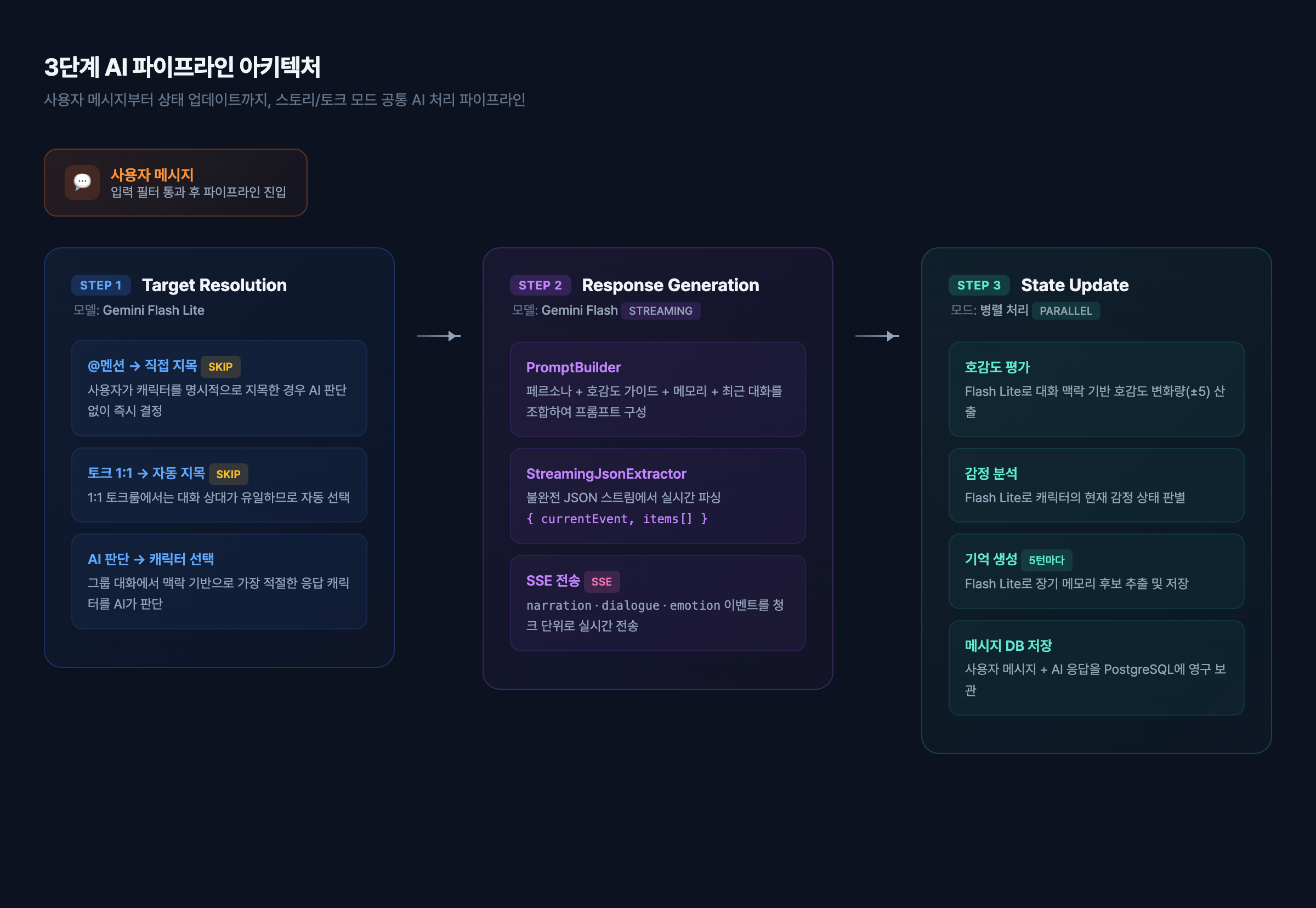
파이프라인의 진입점은 AiPipelineService다. run()은 동기적으로, runStream()은 스트리밍 방식으로 실행된다.
// ai-pipeline.service.ts — 파이프라인 오케스트레이터
async runStream(
context: PipelineContext,
onItem: (item: GeneratedItem) => void,
): Promise<PipelineResult> {
// 1단계: 타겟 결정 + 컨텍스트 빌드
const genContext = await this.buildGenerationContext(context);
// 2단계: 응답 생성 (스트리밍)
const result = await this.responseGeneration.generateStream(
genContext.context,
onItem,
);
// 3단계: 호감도/감정 평가 + 상태 갱신
return this.evaluateAndFinalize(context, genContext, result);
}
onItem 콜백이 핵심이다. 응답이 생성되는 도중에 나레이션이나 대사가 완성될 때마다 호출되어, 컨트롤러가 SSE로 즉시 스트리밍할 수 있다. 전체 응답을 기다릴 필요가 없다.
핵심 1: Target Resolution — 누가 대답할 것인가
스토리 모드에는 캐릭터가 7명이 등장한다. 사용자가 "오늘 날씨 좋다"라고 말했을 때, 누가 대답해야 하는가? 이것을 결정하는 것이 Target Resolution이다.
결정 로직은 세 갈래로 나뉜다.
// ai-pipeline.service.ts — buildGenerationContext 내부
if (context.isTalk && context.characters.length === 1) {
// 토크 1:1 → AI 호출 스킵, 유일한 캐릭터가 대답
targetCharacterName = context.characters[0].name;
} else if (
context.mentionedCharacter &&
nameToId.has(context.mentionedCharacter)
) {
// @ 멘션으로 직접 지목 → 해당 캐릭터가 대답 (장면 부재 시 예외 처리)
// ...
} else {
// AI에게 판단 위임
const targetResult = await this.targetResolution.resolve(
context.userMessage,
context.recentHistory,
context.characters,
context.sceneCharacters,
);
}
AI 판단이 필요한 경우, TargetResolutionService가 경량 모델(Haiku)을 호출한다. 프롬프트에 판단 기준을 우선순위로 명시한다.
// target-resolution.service.ts
const systemPrompt = `너는 인터랙티브 스토리의 대화 라우터이다.
유저의 메시지를 분석하여, 아래 등장인물 중 누가 응답해야 하는지 판단하라.
판단 기준 (우선순위 순):
1. 직접 호명: 유저가 이름을 직접 언급한 경우
2. 맥락 추론: 직전 대화 상대 또는 화제와 관련된 캐릭터
3. 다중 대상: 여러 캐릭터에게 말하는 경우, 가장 적합한 한 명 선택
4. 모호한 경우: 직전에 발화한 캐릭터 선택`;
AI가 실패하거나 유효하지 않은 캐릭터 이름을 반환하면 폴백이 동작한다. 최근 대화에서 마지막으로 발화한 캐릭터, 그마저 없으면 첫 번째 캐릭터를 선택한다.
// target-resolution.service.ts — 폴백
private fallback(recentHistory, characters): TargetResolutionResult {
const lastCharacterMsg = [...recentHistory]
.reverse()
.find((m) => m.senderType === 'character');
const name = lastCharacterMsg?.character?.name
?? characters[0]?.name ?? 'unknown';
return { targetCharacterName: name, confidence: 0.3, reasoning: 'fallback' };
}
또한 부재 캐릭터 시나리오도 처리한다. 사용자가 "@하율아"라고 멘션했지만 하율이 현재 장면에 없는 경우, 대신 장면에 있는 캐릭터 중 적합한 인물을 골라 "여기 없는데?"라는 반응을 유도한다.
핵심 2: Response Generation + Streaming
Target Resolution이 끝나면 본격적인 응답 생성이 시작된다. 이 단계가 파이프라인에서 가장 무겁고, 사용자 체감 지연의 대부분을 차지한다.
시스템 프롬프트 구축
PromptBuilder가 컨텍스트에 따라 동적으로 시스템 프롬프트를 조립한다. 스토리 모드와 토크 모드에서 구성이 다르다.
// prompt-builder.ts — 빌드 흐름
build(): string {
this.parts = [];
if (this.input.isTalk) {
this.buildTalkDirectorSection();
this.buildPlayerInfoSection();
this.buildCharacterProfilesSection();
this.buildTargetEmphasisSection();
this.buildAffinitySection();
this.buildMemoriesSection(); // pgvector RAG 결과
this.buildUserProfileSection(); // 캐릭터별 사용자 팩트
this.buildCharacterStatesSection(); // 이전 턴 내면 상태
this.buildActiveTopicsSection(); // 미결 화제
this.buildRecentHistorySection();
this.buildTalkOutputFormatSection();
} else {
// 스토리 모드: + 씬 컨텍스트, 관계 규칙, 공간 규칙, 줄거리 가이드 등
}
return this.parts.join('\n\n');
}
주목할 부분은 호감도별 행동 가이드다. 단순히 "호감도 45점"이라는 숫자를 주는 것이 아니라, 그 점수가 의미하는 행동 지침을 텍스트로 변환해서 프롬프트에 삽입한다.
// game-rules.ts — 호감도 구간별 행동 가이드
export function getAffinityBehaviorGuide(score: number): string {
if (score <= 15) return '경계/무관심. 시선을 피하고 거리를 유지한다.';
if (score <= 30) return '쿨한 거리두기. 필요한 말만 하고 벽을 세운다.';
if (score <= 45) return '중립~미약한 관심. 가끔 호기심을 보인다.';
if (score <= 60) return '호의적. 은근히 관심을 보이고 가벼운 스킨십에 거부감 없다.';
if (score <= 75) return '뚜렷한 호감. 질투나 독점욕이 살짝 보인다.';
if (score <= 90) return '연애 감정. 둘만의 시간을 원하며 스킨십을 주도하기도 한다.';
return '깊은 유대. 감정 표현이 강렬하고 강한 독점욕.';
}
프롬프트에는 이 외에도 RAG로 조회한 세션 메모리, 최근 15개 메시지, 캐릭터 페르소나, 이벤트 전환 규칙 등이 포함된다.
JSON 스트리밍과 StreamingJsonExtractor
AI 응답 형식은 다음과 같은 JSON 구조다.
{
"currentEvent": "anonymous_msg",
"sceneCharacters": ["한시우", "강도윤", "윤서아"],
"items": [
{"type": "narration", "text": "묘한 침묵이 흘렀다."},
{"type": "dialogue", "character": "한시우", "text": "...뭐야, 왜 다들 조용해."}
],
"characterStates": {
"한시우": {"mood": "불안", "thinking": "뭔가 이상한데..."}
}
}
문제는 이 JSON이 한 번에 오지 않는다는 것이다. 스트리밍으로 토큰 단위로 들어온다. items 배열 안의 객체가 하나씩 완성될 때마다 사용자에게 전달해야 한다.
이를 위해 StreamingJsonExtractor를 구현했다. 핵심은 중괄호 깊이 추적이다.
// streaming-json-extractor.ts
export class StreamingJsonExtractor<T = unknown> {
private buffer = '';
private depth = 0;
private itemStart = -1;
private inString = false; // 문자열 내부 중괄호 무시
private escaped = false; // 이스케이프 시퀀스 처리
private arrayFound = false;
private cursor = 0; // 이미 처리한 위치 — 재스캔 방지
feed(chunk: string): T[] {
this.buffer += chunk;
const items: T[] = [];
// "items": [ 패턴을 찾아 배열 시작 위치 확정
if (!this.arrayFound) {
const pattern = new RegExp(`"${this.arrayKey}"\\s*:\\s*\\[`);
const match = this.buffer.match(pattern);
if (!match) return [];
this.arrayFound = true;
this.cursor = this.buffer.indexOf(match[0]) + match[0].length;
}
for (let i = this.cursor; i < this.buffer.length; i++) {
const ch = this.buffer[i];
// 이스케이프, 문자열 컨텍스트 처리 (생략)
if (ch === '{') {
if (this.depth === 0) this.itemStart = i;
this.depth++;
} else if (ch === '}') {
this.depth--;
if (this.depth === 0 && this.itemStart !== -1) {
// 완전한 객체 하나 완성 → JSON.parse 후 반환
const item = JSON.parse(this.buffer.slice(this.itemStart, i + 1));
items.push(item);
this.itemStart = -1;
}
}
}
this.cursor = this.buffer.length;
return items;
}
}
설계 포인트가 몇 가지 있다.
- cursor로 재스캔 방지:
feed()가 호출될 때마다 이전에 처리한 위치 이후부터만 스캔한다. - 문자열 컨텍스트 인식:
inString플래그로 JSON 문자열 안의{,}를 무시한다."text": "그가 {웃으며} 말했다"같은 경우를 올바르게 처리한다. - 이스케이프 시퀀스:
\"같은 이스케이프된 따옴표가 문자열 종료로 잘못 인식되는 것을 방지한다.
ResponseGenerationService에서의 사용 흐름은 다음과 같다.
// response-generation.service.ts — generateStream 내부
const extractor = new StreamingJsonExtractor<GeneratedItem>('items');
const handleTextDelta = (textDelta: string) => {
fullText += textDelta;
const newItems = extractor.feed(textDelta);
// 완성된 항목마다 즉시 콜백 호출
for (const item of normalized) {
onItem(item);
sentItemCount++;
}
};
스트리밍이 끝난 후에는 전체 텍스트를 다시 파싱해서 혹시 놓친 항목이 없는지 확인한다. 잘린 JSON도 StreamingJsonExtractor를 복구 도구로 재활용한다.
핵심 3: 멀티모델 오케스트레이션
Plit은 하나의 AI 모델만 쓰지 않는다. 작업의 성격에 따라 다른 모델을 배정한다.
| 작업 | 모델 | 이유 |
|---|---|---|
| 응답 생성 (대사/나레이션) | Gemini Flash / Claude Sonnet | 창작 품질이 중요. 캐릭터 페르소나, 호감도 뉘앙스, 서사 일관성 |
| Target Resolution | Haiku | 단순 분류 작업. "누가 대답할지"만 결정하면 됨 |
| 호감도 평가 | Haiku | ±5 범위의 보수적 판단. 입출력이 작음 |
| 감정 분석 | Haiku | 15개 감정 태그 중 하나 선택 |
| 메모리 생성 | Haiku | 대화 요약. 5턴마다 1회 |
AiClientService는 런타임에 provider를 전환할 수 있다. Redis에 settings:ai_provider 값을 저장하고, 요청마다 확인한다.
// ai-client.service.ts
async getProvider(): Promise<'claude' | 'gemini'> {
const val = await this.redis.get(SETTINGS_KEY);
return val === 'claude' ? 'claude' : 'gemini';
}
경량 작업에 비싼 모델을 쓸 필요가 없고, 창작 작업에 싼 모델을 쓰면 품질이 떨어진다. 이 분리가 비용과 품질 양쪽을 잡는 핵심이다.
핵심 4: POST-based SSE
왜 네이티브 EventSource를 쓰지 않는가
브라우저의 EventSource API는 GET 요청만 지원한다. Plit의 메시지 전송은 content, mentionedCharacter, forceAdvanceEvent 등의 본문이 필요하다. GET 쿼리 파라미터로 전달하기에는 부적절하다.
대신 POST 요청 + res.write() 수동 SSE를 사용한다.
백엔드: SSE 이벤트 구조
// sse-events.ts — 이벤트 타입 정의
export const SSE_EVENTS = {
NARRATION: 'narration',
DIALOGUE: 'dialogue',
EMOTION: 'emotion',
DONE: 'done',
ERROR: 'error',
} as const;
컨트롤러에서 SSE 헤더를 설정하고 res.write()로 이벤트를 하나씩 내려보낸다.
// chat.controller.ts — sendMessage 핵심 흐름
res.setHeader('Content-Type', 'text/event-stream');
res.setHeader('Cache-Control', 'no-cache');
res.setHeader('Connection', 'keep-alive');
// 파이프라인을 스트리밍 모드로 실행
const result = await this.aiPipelineService.runStream(
pipelineContext,
(item) => {
if (item.type === 'narration') {
res.write(
`event: narration\ndata: ${JSON.stringify({ text: item.text })}\n\n`,
);
} else if (item.type === 'dialogue') {
res.write(
`event: dialogue\ndata: ${JSON.stringify({
character: item.character,
text: item.text,
})}\n\n`,
);
}
},
);
// 스트리밍 완료 후 후처리 결과 전송
for (const emo of result.emotions) {
res.write(
`event: emotion\ndata: ${JSON.stringify({
character: emo.character,
emotion: emo.emotion,
})}\n\n`,
);
}
res.write(`event: done\ndata: ${JSON.stringify({
userMessageId: savedMsg.id,
aiMessageIds,
affinities: doneData.finalAffinities,
// ...
})}\n\n`);
res.end();
이벤트 순서가 중요하다. narration/dialogue는 AI가 생성하는 즉시 스트리밍되고, emotion과 done은 파이프라인 완료 후에 전송된다. 프론트엔드는 done 이벤트를 받으면 스트림 소비를 종료한다.
에러 처리와 재화 롤백
스트리밍 중 에러가 발생하면, 이미 소비한 행동력과 젬을 롤백한다.
// chat.controller.ts — 에러 핸들링
} catch (error) {
// 행동력 환불
await this.energyService.refundEnergy(userId, ENERGY_CONSTANTS.COST_PER_ACTION);
// 자동 젬 충전이 있었다면 젬도 환불
if (energyResult.gemCharged) {
await this.gemsService.refund(userId, GemTransactionReason.ENERGY_CHARGE, sessionId);
}
res.write(`event: error\ndata: ${JSON.stringify({
message: 'AI 응답 생성에 실패했습니다. 행동력과 젬이 환불되었습니다.',
code: 'AI_GENERATION_FAILED',
energyRefunded: true,
gemRefunded: true,
})}\n\n`);
res.end();
}
입력 필터(블랙리스트)에 걸린 경우에도 동일하게 롤백 후 error → done 순서로 스트림을 종료한다.
프론트엔드: ReadableStream 파싱
네이티브 EventSource를 쓰지 않으므로, fetch 응답의 ReadableStream을 직접 파싱한다. event: 라인과 data: 라인을 분리하여 이벤트 타입별로 콜백을 실행하는 구조다.
정리
- 파이프라인을 단계별로 분리하라. "누가 대답할지"와 "뭐라고 말할지"는 별개의 문제다. 분리하면 각 단계를 독립적으로 모델 교체하거나 최적화할 수 있다.
- 경량 모델을 적극 활용하라. Target Resolution 같은 분류 작업에 대형 모델을 쓸 이유가 없다. 비용은 줄이고, 응답 속도도 빨라진다.
- 스트리밍 JSON 파싱은 상태 머신이다. 중괄호 깊이 추적 + 문자열 컨텍스트 인식 + 이스케이프 처리. 이 셋을 빠뜨리면 파싱이 깨진다.
- POST-based SSE는 EventSource의 실용적 대안이다. GET 제약을 우회하면서 SSE의 이점(이벤트 타입 구분, 점진적 전송)은 그대로 유지할 수 있다.
- 호감도를 숫자가 아니라 행동 지침으로 변환하라. AI에게 "45점"이라고 주는 것보다 "중립~미약한 관심. 가끔 호기심을 보인다"라고 주는 것이 훨씬 효과적이다.
- 콘텐츠 필터는 스트리밍 중에도 동작해야 한다. 전체 응답을 기다렸다가 필터링하면 이미 사용자에게 노출된 후다.
onItem콜백 안에서 실시간으로 검사한다. - 재화 소비가 있는 API는 반드시 롤백을 설계하라. AI 파이프라인은 실패할 수 있다. 행동력과 젬을 먼저 차감하고, 실패 시 환불하는 패턴을 적용했다.