왜 콘텐츠 안전 필터링이 필요한가
AI 채팅 플랫폼에서 콘텐츠 안전은 선택이 아니라 필수다. 사용자가 자유롭게 텍스트를 입력하고, AI가 자유롭게 텍스트를 생성하는 구조에서는 양쪽 모두에서 부적절한 콘텐츠가 발생할 수 있다.
영어 기반 필터링은 비교적 단순하다. 단어 단위로 매칭하면 대부분의 케이스를 잡아낸다. 그러나 한국어는 상황이 전혀 다르다.
한국어의 "섹스"라는 단어 하나를 차단하려면, "섹 스", "ㅅㅔㄱㅅㅡ", "섹 스"(전각 공백), "sㅔㄱ스" 같은 변형을 모두 고려해야 한다.
한국어는 자모 분리, 공백 삽입, 유니코드 정규화 차이 등 텍스트 우회 벡터가 다양하다. Plit에서는 이를 체계적으로 방어하기 위해 정규화 파이프라인과 양방향 필터링 시스템을 구축했다. 그 과정을 기록한다.
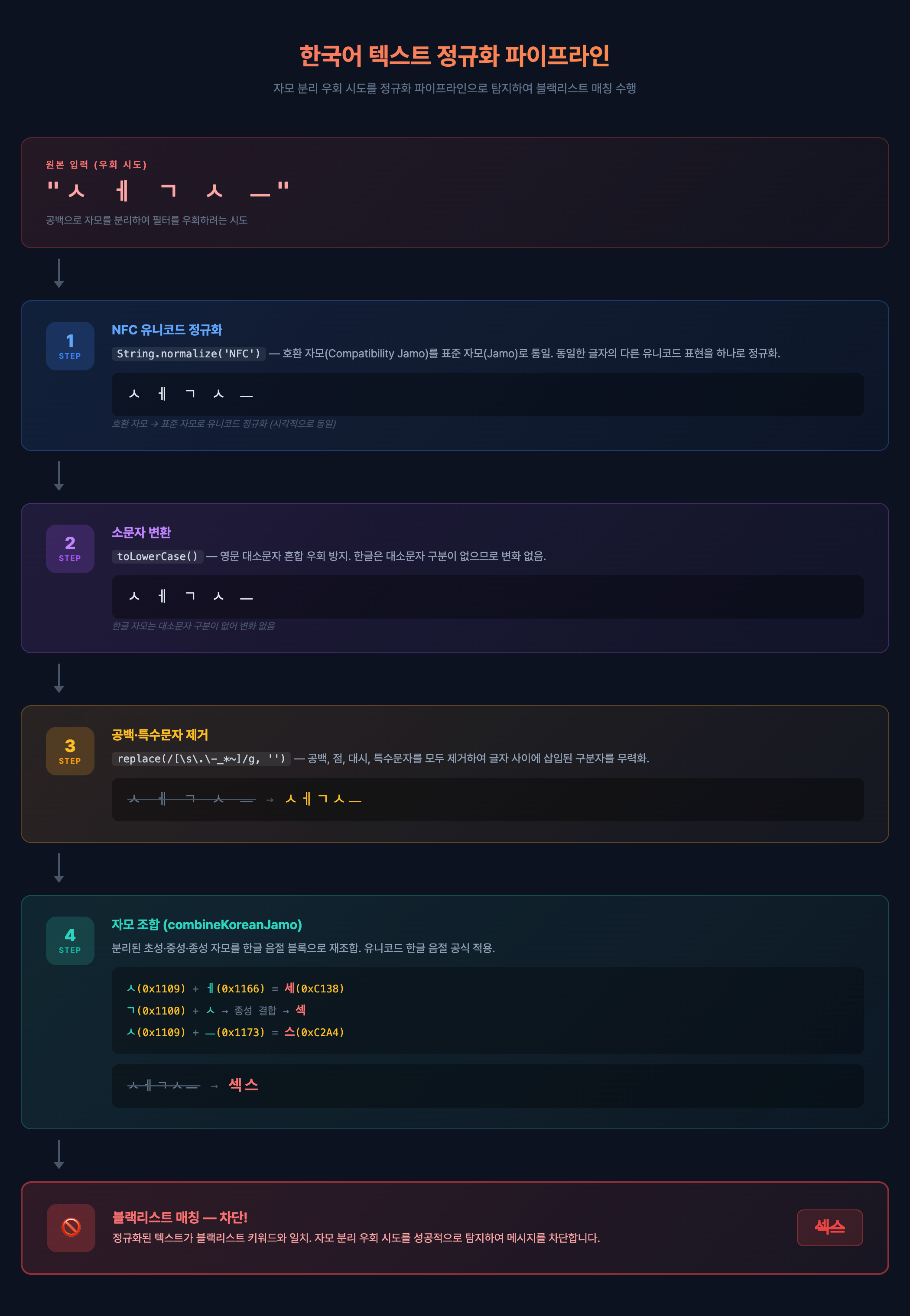
핵심 1: 한국어 텍스트 정규화 파이프라인
필터링의 핵심은 비교 대상을 동일한 형태로 정규화하는 것이다. 사용자 입력과 블랙리스트 키워드를 모두 같은 파이프라인에 통과시키면, 어떤 변형을 사용하든 결국 같은 문자열로 수렴한다.
// content-safety.service.ts — 4단계 정규화 파이프라인
private normalizeText(text: string): string {
// 1. Unicode NFC 정규화 — 조합형/완성형 통일
let normalized = text.normalize('NFC');
// 2. 소문자 변환 — 영문 대소문자 우회 방지
normalized = normalized.toLowerCase();
// 3. 공백 제거 — "아 동" → "아동" 우회 차단
normalized = normalized.replace(/\s+/g, '');
// 4. 자모 조합 — ㅇㅏㄷㅗㅇ → 아동
normalized = this.combineKoreanJamo(normalized);
return normalized;
}
각 단계에는 명확한 이유가 있다.
1단계: Unicode NFC 정규화. 유니코드에는 같은 한국어 글자를 표현하는 방법이 여러 가지 있다. NFD(Normalization Form Decomposed)에서는 "가"가 초성+중성 조합형으로 저장되고, NFC(Normalization Form Composed)에서는 완성형 한 글자로 저장된다. 브라우저, OS, 입력기에 따라 어떤 형태가 넘어올지 알 수 없기 때문에 NFC로 먼저 통일한다.
2단계: 소문자 변환. 한국어 자체에는 대소문자가 없지만, "SEX"와 "sex"처럼 영문이 섞인 우회를 막기 위해 필요하다.
3단계: 공백 제거. 가장 흔한 우회 수법이다. "금 지 어"처럼 글자 사이에 공백을 넣으면 단순 문자열 매칭을 피할 수 있다. 정규화 단계에서 모든 공백을 제거하면 이 우회를 원천 차단할 수 있다.
4단계: 자모 조합. 한국어 특유의 우회 방식이다. 다음 절에서 자세히 다룬다.
checkText()는 이 정규화를 사용자 입력과 블랙리스트 키워드 양쪽 모두에 적용한다.
// content-safety.service.ts — 정규화된 문자열끼리 비교
checkText(
text: string,
blacklist: string[],
): { flagged: boolean; matchedKeywords: string[] } {
const normalized = this.normalizeText(text);
const matchedKeywords: string[] = [];
for (const keyword of blacklist) {
const normalizedKeyword = this.normalizeText(keyword);
if (normalized.includes(normalizedKeyword)) {
matchedKeywords.push(keyword);
}
}
return {
flagged: matchedKeywords.length > 0,
matchedKeywords,
};
}
블랙리스트에는 원본 형태("섹스")만 등록하면 된다. 정규화가 양쪽 모두에 적용되므로 "ㅅㅔㄱㅅㅡ"든 "섹 스"든 모두 잡아낸다.
핵심 2: 자모 조합 — ㅇㅏㄷㅗㅇ은 어떻게 "아동"이 되는가
한국어 유니코드 음절의 구조를 이해해야 한다. 완성형 한글 한 글자는 초성 + 중성 + (종성) 으로 구성되며, 유니코드 코드포인트로 다음 공식이 성립한다.
코드포인트 = (초성 × 21 + 중성) × 28 + 종성 + 0xAC00
예를 들어 "동"을 만들려면: 초성 ㄷ(인덱스 3) × 21 + 중성 ㅗ(인덱스 8) = 71, 71 × 28 + 종성 ㅇ(인덱스 21) = 2009, 2009 + 0xAC00 = 0xB3D9 — 이것이 "동"의 유니코드 코드포인트다.
자모 조합을 구현하려면 먼저 호환 자모(0x3131~0x3163 범위)를 초성·중성·종성 인덱스로 변환하는 매핑 테이블이 필요하다.
// 초성 매핑: 호환 자모 코드 → 초성 인덱스 (0~18)
const CHOSEONG_MAP: Record<number, number> = {
0x3131: 0, // ㄱ
0x3132: 1, // ㄲ
0x3134: 2, // ㄴ
0x3137: 3, // ㄷ
// ... 총 19개 초성
0x314e: 18, // ㅎ
};
// 중성 매핑: 호환 자모 코드 → 중성 인덱스 (0~20)
const JUNGSEONG_MAP: Record<number, number> = {
0x314f: 0, // ㅏ
0x3150: 1, // ㅐ
0x3151: 2, // ㅑ
// ... 총 21개 중성
0x3163: 20, // ㅣ
};
// 종성 매핑: 호환 자모 코드 → 종성 인덱스 (1~27, 0은 종성 없음)
const JONGSEONG_MAP: Record<number, number> = {
0x3131: 1, // ㄱ
0x3132: 2, // ㄲ
0x3134: 4, // ㄴ
// ... 총 16개 종성
0x314e: 27, // ㅎ
};
핵심은 호환 자모(Compatibility Jamo, 0x31310x3163)와 조합용 자모(Conjoining Jamo, 0x11000x11C2)가 다르다는 점이다. 사용자가 키보드로 자모를 하나씩 입력하면 호환 자모 범위의 코드포인트가 생성되는데, 이를 초성/중성/종성으로 분류하여 완성형 글자로 합쳐야 한다.
조합 알고리즘의 핵심 로직은 다음과 같다.
// content-safety.service.ts — 자모 조합 핵심 로직
private combineKoreanJamo(text: string): string {
const result: string[] = [];
let i = 0;
while (i < text.length) {
const code = text.charCodeAt(i);
// 현재 문자가 초성이고, 다음 문자가 중성인 경우
if (this.isChoseong(code) && i + 1 < text.length) {
const nextCode = text.charCodeAt(i + 1);
if (this.isJungseong(nextCode)) {
const cho = CHOSEONG_MAP[code];
const jung = JUNGSEONG_MAP[nextCode];
let jong = 0;
// 종성 후보 확인: 세 번째 문자가 자음인 경우
if (i + 2 < text.length) {
const thirdCode = text.charCodeAt(i + 2);
if (this.isChoseong(thirdCode)) {
// 핵심 판단: 다음 글자의 초성인가, 현재 글자의 종성인가?
// → 뒤에 모음이 오면 다음 글자의 초성, 아니면 종성
if (
i + 3 >= text.length ||
!this.isJungseong(text.charCodeAt(i + 3))
) {
if (JONGSEONG_MAP[thirdCode] !== undefined) {
jong = JONGSEONG_MAP[thirdCode];
i += 3;
result.push(
String.fromCharCode(
(cho * 21 + jung) * 28 + jong + 0xac00
),
);
continue;
}
}
}
}
// 종성 없이 조합
result.push(
String.fromCharCode((cho * 21 + jung) * 28 + jong + 0xac00),
);
i += 2;
continue;
}
}
result.push(text[i]);
i++;
}
return result.join('');
}
이 알고리즘에서 가장 미묘한 부분은 종성/초성 경계 판단이다. "ㅇㅏㄷㅗㅇ"을 처리할 때, 세 번째 문자 "ㄷ"은 "아"의 종성이 아니라 "동"의 초성이다. 이를 판단하는 방법은 단순하다 — 뒤에 모음이 오면 다음 글자의 초성, 아니면 현재 글자의 종성이다. "ㄷ" 뒤에 "ㅗ"(모음)가 오므로 "ㄷ"은 다음 글자의 초성이 된다.
테스트 코드가 이 동작을 검증한다.
// content-safety.service.spec.ts
it('should detect sexual keywords in jamo form (bypass attempt)', () => {
// "ㅅㅔㄱㅅㅡ" → 정규화 → "섹스"
const result = service.checkText('ㅅㅔㄱㅅㅡ', sexualKeywords);
expect(result.flagged).toBe(true);
});
핵심 3: 양방향 필터링 — 입력과 출력 모두 감시한다
AI 채팅에서는 필터링 지점이 두 곳 있다. 사용자 입력(AI가 처리하기 전)과 AI 출력(사용자에게 전달되기 전)이다. Plit은 POST-based SSE 스트리밍 방식으로 대화가 이루어지므로, 출력 필터링은 스트리밍 중 실시간으로 수행해야 한다.
입력 필터: 블랙리스트 차단 + 재화 환불
사용자가 메시지를 보내면 행동력(Energy)이 소비된다. 입력 필터에서 차단되면 대화가 진행되지 않았으므로 소비된 행동력과 젬을 환불해야 한다.
// chat.controller.ts — 입력 필터링 + 환불 로직
// 입력 필터: 블랙리스트 키워드 검사
const blacklist = await this.contentSafety.loadBlacklist();
const inputCheck = this.contentSafety.checkText(content, blacklist);
if (inputCheck.flagged) {
await this.contentSafety.logSafetyEvent({
sessionId,
userId: (req as { user?: { userId?: string } }).user?.userId,
filterStage: 'input',
originalContent: content,
matchedKeywords: inputCheck.matchedKeywords,
action: 'blocked',
});
// BIL-016: 입력 필터 차단 시 행동력(+젬) 환불
if (energyResult) {
await this.energyService.refundEnergy(
userId, ENERGY_CONSTANTS.COST_PER_ACTION
);
if (energyResult.gemCharged) {
await this.gemsService.refund(
userId, GemTransactionReason.ENERGY_CHARGE, sessionId
);
}
}
// SSE 에러 이벤트로 차단 사유 전송
res.write(`event: error\ndata: ${JSON.stringify({
message: '부적절한 내용이 포함되어 있어 전송할 수 없습니다.',
code: 'INPUT_FILTER_BLOCKED',
energyRefunded: true,
gemRefunded,
})}\n\n`);
res.end();
return;
}
입력 필터의 흐름은 이렇다: 메시지 수신 → 행동력 차감 → 블랙리스트 검사 → 차단 시 행동력+젬 환불 → SSE 에러 이벤트 전송 → 연결 종료.
출력 필터: 스트리밍 중 실시간 차단
AI 출력 필터링은 더 까다롭다. AI가 생성한 텍스트가 청크 단위로 스트리밍되는 도중에 각 항목을 실시간으로 검사해야 한다. 부적절한 내용이 감지되면 해당 청크를 대체 나레이션으로 교체한다.
// chat.controller.ts — 스트리밍 중 출력 필터링
const result = await this.aiPipelineService.runStream(
pipelineContext,
(item) => {
// 출력 필터: 블랙리스트 키워드 검사
const outputCheck = this.contentSafety.checkText(
item.text, blacklist
);
if (outputCheck.flagged) {
this.contentSafety.logSafetyEvent({
sessionId,
filterStage: 'output',
originalContent: item.text,
matchedKeywords: outputCheck.matchedKeywords,
action: 'replaced',
}).catch((err) => this.logger.warn('Safety log failed', err));
// 대체 나레이션 전송
res.write(
`event: narration\ndata: ${JSON.stringify({
text: '묘한 침묵이 흘렀다.'
})}\n\n`
);
return;
}
// 정상 콘텐츠 스트리밍
if (item.type === 'narration') {
res.write(`event: narration\ndata: ${JSON.stringify({
text: item.text
})}\n\n`);
} else if (item.type === 'dialogue') {
res.write(`event: dialogue\ndata: ${JSON.stringify({
character: item.character, text: item.text
})}\n\n`);
}
},
);
출력 필터에서 주목할 점은 **action이 'blocked'가 아니라 'replaced'**라는 것이다. 입력은 완전히 차단하지만, 출력은 대체 나레이션("묘한 침묵이 흘렀다.")으로 교체하여 대화 흐름을 유지한다. 사용자 입장에서는 자연스러운 나레이션 하나가 삽입될 뿐, 필터링이 발생했다는 사실을 노골적으로 인지하지 못한다.

NSFW 패턴 가드: 호감도 조작 방지
블랙리스트 필터 외에 별도의 NSFW 패턴 가드가 AI 파이프라인 내부에 있다. 이것은 메시지를 차단하는 것이 아니라, 성적 콘텐츠를 통해 호감도를 올리는 시도를 방지한다.
// ai-pipeline.service.ts — 정적 NSFW 패턴
private static readonly NSFW_PATTERNS = [
/섹스/, /성관계/, /성행위/, /자위/,
/가슴.*벗/, /벗.*가슴/, /옷.*벗/, /벗.*옷/,
// ... 총 17개 패턴
];
// NSFW 감지 시 호감도 양수 차단
if (this.containsNsfwContent(userMessage, aiResponseText)) {
rawAffinityChanges = rawAffinityChanges.map((c) => ({
...c,
delta: Math.min(0, c.delta), // 양수를 0으로 클램핑
reason: c.delta > 0
? `${c.reason} [NSFW 가드: 긍정 변화 차단]`
: c.reason,
}));
}
이 가드는 "성적 대화를 하면 호감도가 올라간다"는 게임 플레이 악용을 차단한다. 호감도는 0 이하로만 변동하되 대화 자체를 중단하지는 않는다.
핵심 4: Redis 캐싱과 감사 로그
블랙리스트 Redis 캐싱
블랙리스트는 매 메시지마다 조회된다. 입력과 출력 모두에서 사용하므로 하나의 메시지 처리에 최소 두 번은 참조한다. DB를 매번 조회하면 성능 병목이 되므로 Redis에 1시간 TTL로 캐싱한다.
// content-safety.service.ts — Redis 캐싱
const BLACKLIST_CACHE_KEY = 'safety:blacklist';
const BLACKLIST_CACHE_TTL = 3600; // 1시간
async loadBlacklist(): Promise<string[]> {
const cached = await this.redis.get(BLACKLIST_CACHE_KEY);
if (cached) {
try {
return JSON.parse(cached) as string[];
} catch {
await this.redis.del(BLACKLIST_CACHE_KEY); // 파싱 실패 시 캐시 삭제
}
}
// DB에서 활성 키워드만 조회
const keywords = await this.prisma.blacklistKeyword.findMany({
where: { isActive: true },
select: { keyword: true },
});
const list = keywords.map((k) => k.keyword);
await this.redis.set(BLACKLIST_CACHE_KEY, JSON.stringify(list), {
ex: BLACKLIST_CACHE_TTL,
});
return list;
}
Admin에서 블랙리스트를 수정하면 refreshBlacklistCache()로 캐시를 즉시 갱신할 수 있다.
감사 로그
모든 필터링 이벤트는 content_safety_logs 테이블에 기록된다. 누가, 어떤 세션에서, 어떤 단계(input/output)에서, 무슨 키워드에 걸렸고, 어떤 조치(blocked/replaced)를 취했는지 추적할 수 있다.
model ContentSafetyLog {
id String @id @default(uuid())
sessionId String? @map("session_id")
userId String? @map("user_id")
filterStage String @map("filter_stage") // 'input' | 'output'
originalContent String @map("original_content")
matchedKeywords String[] @map("matched_keywords")
action String // 'blocked' | 'replaced'
createdAt DateTime @default(now())
@@index([sessionId])
@@index([userId])
@@index([createdAt])
}
블랙리스트 키워드에는 카테고리가 있어서(child_safety, crime, non_consent, custom) 어떤 유형의 위반이 얼마나 발생하는지 분석할 수 있다. 이 로그 데이터는 콘텐츠 안전 정책 고도화의 기반이 된다.
정리
- 한국어 필터링은 단순 문자열 매칭으로는 부족하다. 자모 분리, 공백 삽입, 유니코드 정규화 차이 등 한국어 고유의 우회 벡터를 체계적으로 막아야 한다.
- 정규화 파이프라인이 핵심이다. NFC → lowercase → 공백 제거 → 자모 조합의 4단계를 거치면 대부분의 변형을 하나의 형태로 수렴시킬 수 있다.
- 유니코드 한글 조합 공식
(초성 × 21 + 중성) × 28 + 종성 + 0xAC00은 외워둘 가치가 있다. 이 공식 하나로 자모를 완성형 글자로 합칠 수 있다. - 종성/초성 경계 판단은 한 글자 앞을 더 봐야 한다. 연속된 자모에서 자음이 현재 글자의 종성인지 다음 글자의 초성인지는 그 뒤에 모음이 있는지로 결정된다.
- 입력 필터와 출력 필터의 전략은 달라야 한다. 입력은 완전 차단 + 재화 환불, 출력은 대체 나레이션으로 자연스럽게 교체한다.
- 블랙리스트의 성능은 캐싱으로 해결한다. 매 메시지마다 DB를 조회하지 않고 Redis에 TTL 기반으로 캐싱하면 된다.
- 감사 로그는 필터링만큼 중요하다. 차단 사실을 기록하지 않으면 정책을 개선할 데이터가 없다. filterStage, matchedKeywords, action을 구조화하여 저장해야 나중에 분석할 수 있다.