문제: 컨텍스트 윈도우의 한계
AI 캐릭터 채팅 서비스에서 가장 먼저 부딪히는 벽은 컨텍스트 윈도우다. LLM에 보낼 수 있는 토큰 수에는 상한이 있고, 대화가 길어질수록 초반 내용은 잘려 나간다. 15턴짜리 최근 대화 기록만으로 프롬프트를 구성하면, 30턴 전에 사용자가 캐릭터에게 한 고백이나 약속은 흔적도 없이 사라진다.
AI 캐릭터가 "어제 네가 해준 말 기억나?" 라는 질문에 "무슨 말이었는데?" 라고 답한다면, 몰입은 깨진다.
Plit에서는 이 문제를 선택적 기억 회상(Selective Memory Recall)으로 해결한다. 대화를 주기적으로 요약해서 저장하고, 현재 대화 맥락과 가장 관련 높은 기억만 골라 프롬프트에 주입하는 구조다. 이 글에서는 그 구현 과정을 코드와 함께 정리한다.
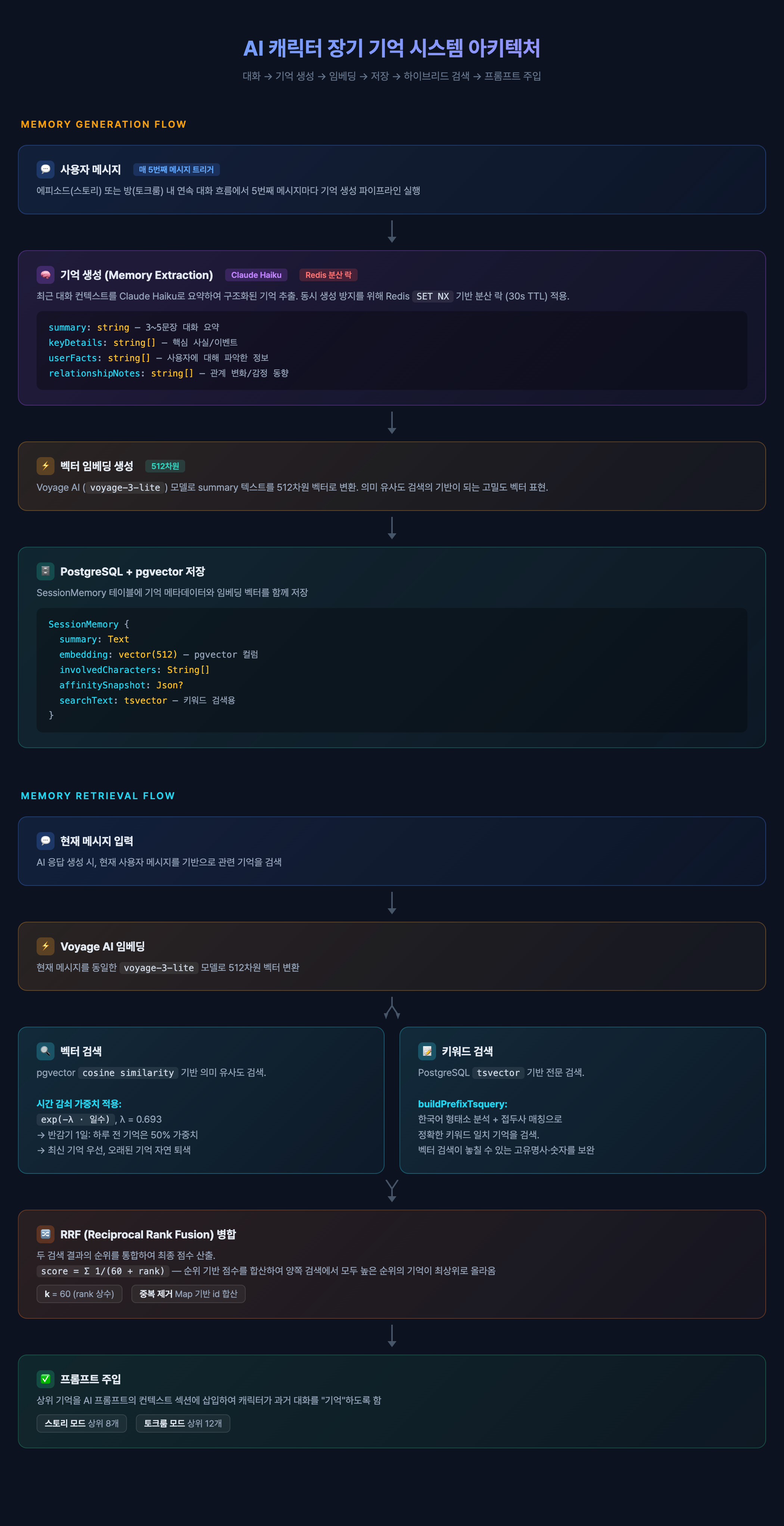
1. 주기적 대화 요약 생성
트리거 조건: 사용자 메시지 5회
메모리 생성의 트리거는 단순하다. 마지막 메모리 생성 이후 사용자 메시지가 5개 이상 쌓이면 생성을 시작한다.
// memory.service.ts — 메모리 생성 트리거 판단
async shouldGenerateMemory(sessionId: string): Promise<boolean> {
const lastMemory = await this.prisma.sessionMemory.findFirst({
where: { sessionId },
orderBy: { createdAt: 'desc' },
});
const since = lastMemory?.messageRangeEnd ?? new Date(0);
const userMsgCount = await this.prisma.chatMessage.count({
where: {
sessionId,
senderType: 'user',
createdAt: { gt: since },
},
});
return userMsgCount >= 5;
}
시스템 메시지(나레이션 삽입 등)는 카운트에서 제외한다. 사용자의 능동적 참여 5회가 기준이다.
Redis 분산 락으로 중복 방지
AI 응답 생성은 비동기이므로, 동시에 여러 요청이 메모리 생성을 시도할 수 있다. Redis의 SET NX(Not eXists)를 사용해 30초 TTL의 분산 락을 건다.
// memory.service.ts — Redis NX 락으로 동시 생성 방지
async generateMemory(sessionId: string, ...): Promise<MemoryGenerationResult> {
const lockKey = `memory:gen:${sessionId}`;
const acquired = await this.redis.set(lockKey, '1', { ex: 30, nx: true });
if (!acquired) return { created: false };
try {
// ... 메모리 생성 로직
} finally {
await this.redis.del(lockKey); // 완료 후 락 해제
}
}
nx: true이므로 이미 키가 존재하면 null을 반환한다. 첫 번째 요청만 락을 획득하고, 나머지는 { created: false }로 즉시 리턴된다. try/finally로 락 해제를 보장하되, 만약 프로세스가 죽더라도 ex: 30(30초 TTL)이 걸려 있어 락이 영원히 남지 않는다.
AI 요약: 무엇을 기억하는가
요약 생성은 Claude Haiku 4.5에 위임한다. 단순 요약이 아니라, 구조화된 JSON으로 다섯 가지 축을 추출한다.
| 추출 항목 | 설명 |
|---|---|
summary | 3~5문장 한국어 요약. 사건, 감정 변화, 관계 역학 포함 |
keyDetails | 인상적인 대사(quote)와 행동(action) 최대 10개를 원문 그대로 보존 |
userFacts | 사용자가 스스로 밝힌 정보 (취미, 직업 등)를 캐릭터별로 기록 |
relationshipNotes | 캐릭터-사용자 관계 동향 (우호/긴장/적대 등) |
activeTopics | 아직 해결되지 않은 미결 화제 최대 5개 |
keyDetails에는 절대 규칙이 있다. 사용자("나")가 각 캐릭터에게 한 대사/행동을 캐릭터별로 최소 1개씩 반드시 포함해야 한다. "내가 그 캐릭터에게 뭐라고 했지?" 라는 질문에 정확히 답하기 위해서다.
2. Voyage AI 임베딩과 pgvector 저장
벡터 임베딩 생성
요약 텍스트를 Voyage AI의 voyage-3-lite 모델로 512차원 벡터에 매핑한다.
// memory.service.ts — Voyage AI 임베딩 생성
private async generateEmbedding(text: string): Promise<number[] | null> {
try {
const response = await fetch('https://api.voyageai.com/v1/embeddings', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
Authorization: `Bearer ${this.voyageApiKey}`,
},
body: JSON.stringify({
input: [text],
model: this.voyageModel, // 'voyage-3-lite'
}),
});
if (!response.ok) {
this.logger.warn(`Voyage API error: ${response.status}`);
return null; // 실패 시 null 반환 → 최신순 폴백
}
const data = (await response.json()) as {
data: { embedding: number[] }[];
};
return data.data[0].embedding;
} catch (error) {
this.logger.warn(`Embedding generation failed: ${error}`);
return null;
}
}
voyage-3-lite를 선택한 이유는 비용과 속도다. 한국어 대화 요약은 보통 100~200자 내외이므로 고차원 모델이 필요 없고, 512차원이면 충분한 의미 분별력을 얻을 수 있다.
pgvector 컬럼과 tsvector 컬럼
Prisma 스키마에서 SessionMemory 모델은 두 개의 검색 컬럼을 갖는다.
// schema.prisma — SessionMemory 모델 (검색 컬럼)
model SessionMemory {
id String @id @default(uuid())
sessionId String @map("session_id")
type String @default("short_term")
summary String @db.Text
involvedCharacters String[] @map("involved_characters")
keyDetails Json? @map("key_details") @db.JsonB
embedding Unsupported("vector(512)")? // pgvector 시맨틱 검색
searchVector Unsupported("tsvector")? // 키워드 검색
// ...
}
Prisma의 Unsupported 타입은 ORM이 직접 다루지 못하는 PostgreSQL 네이티브 타입을 선언하는 용도다. 읽기/쓰기는 raw SQL로 처리한다.
// memory.service.ts — 메모리 저장 후 벡터 + tsvector 업데이트
if (this.voyageApiKey) {
const embedding = await this.generateEmbedding(parsed.summary);
if (embedding) {
const vectorStr = `[${embedding.join(',')}]`;
await this.prisma.$executeRawUnsafe(
`UPDATE session_memories SET embedding = $1::vector WHERE id = $2`,
vectorStr,
memory.id,
);
}
}
// 키워드 검색용 tsvector (항상 저장)
await this.prisma.$executeRawUnsafe(
`UPDATE session_memories SET search_vector = to_tsvector('simple', $1) WHERE id = $2`,
parsed.summary,
memory.id,
);
Graceful Fallback
VOYAGE_API_KEY가 없거나 API 호출이 실패하면 임베딩 없이 저장된다. 검색 시에도 동일한 패턴으로 폴백한다.
// memory-retrieval.service.ts — 임베딩 불가 시 최신순 폴백
if (!this.voyageApiKey) {
return this.getRecentMemories(sessionIds, effectiveLimit, characterName);
}
const queryEmbedding = await this.generateEmbedding(query);
if (!queryEmbedding) {
return this.getRecentMemories(sessionIds, effectiveLimit, characterName);
}
Voyage API가 다운되어도 서비스가 중단되지 않는다. 최신순으로 기억을 가져오는 것은 시맨틱 검색보다 정확도가 떨어지지만, 아무 기억도 못 꺼내는 것보다는 낫다.
3. 하이브리드 검색: 벡터 + 키워드
검색 시에는 두 경로를 동시에 실행한다.
경로 A: pgvector 코사인 유사도 + 시간 감쇠
-- 시간 감쇠 가중 코사인 유사도 (반감기 1일)
(1 - (embedding <=> $2::vector))
* EXP(-0.693 * EXTRACT(EPOCH FROM (NOW() - created_at)) / 86400.0)
<=> 연산자는 pgvector의 코사인 거리다. 1 - 거리로 유사도를 구한 뒤, 지수 감쇠 함수를 곱한다. 상수 0.693은 ln(2)로, 이 공식은 1일(86,400초) 반감기를 의미한다. 즉 하루 전 기억은 유사도의 절반, 이틀 전은 1/4로 점수가 줄어든다.
왜 시간 감쇠가 필요한가? 의미적으로 비슷한 기억이 여러 개 있을 때, 최근 기억이 더 관련성이 높을 확률이 크기 때문이다. "어제 카페에서 커피 마신 이야기"와 "일주일 전 카페에서 커피 마신 이야기"가 둘 다 유사하지만, 사용자가 "커피 기억나?"라고 물었을 때 원하는 건 대부분 어제 이야기다.
// memory-retrieval.service.ts — pgvector 검색
private async getVectorResults(
sessionIds: string[], vectorStr: string, limit: number, characterName?: string,
): Promise<MemoryResult[]> {
const scoreSql = `(1 - (embedding <=> $2::vector)) * EXP(-0.693 * EXTRACT(EPOCH FROM (NOW() - created_at)) / 86400.0)`;
const rows: MemoryResult[] = await this.prisma.$queryRawUnsafe(
`SELECT id, summary, involved_characters AS "involvedCharacters",
key_details AS "keyDetails", created_at AS "createdAt"
FROM session_memories
WHERE session_id = ANY($1::text[])
ORDER BY ${scoreSql} DESC
LIMIT $3`,
sessionIds, vectorStr, limit,
);
return this.decryptMemoryResults(rows);
}
경로 B: tsvector 키워드 검색
// memory-retrieval.service.ts — tsvector 키워드 검색
private async getTextSearchResults(
sessionIds: string[], query: string, limit: number, characterName?: string,
): Promise<MemoryResult[]> {
const tsquery = MemoryRetrievalService.buildPrefixTsquery(query);
if (!tsquery) return [];
const rows: MemoryResult[] = await this.prisma.$queryRawUnsafe(
`SELECT id, summary, involved_characters AS "involvedCharacters",
key_details AS "keyDetails", created_at AS "createdAt"
FROM session_memories
WHERE session_id = ANY($1::text[])
AND search_vector @@ to_tsquery('simple', $2)
ORDER BY ts_rank(search_vector, to_tsquery('simple', $2)) DESC
LIMIT $3`,
sessionIds, tsquery, limit,
);
return this.decryptMemoryResults(rows);
}
한국어에서 simple 토크나이저는 조사를 분리하지 못한다. "한시우가"와 "한시우를"이 다른 토큰이 되는 문제가 있다. 이를 접두사 매칭으로 보완한다.
// memory-retrieval.service.ts — 한국어 접두사 매칭 tsquery 생성
// "한시우 위스키" → "한시우:* & 위스키:*"
private static buildPrefixTsquery(query: string): string {
return query
.trim()
.replace(/[()&|!<>:*\\."']/g, ' ')
.split(/\s+/)
.filter((w) => w.length > 0)
.map((w) => `${w}:*`)
.join(' & ');
}
한시우:*는 "한시우"로 시작하는 모든 토큰과 매칭된다. 조사가 붙어도("한시우가", "한시우에게") 검색이 된다. 완벽하지는 않지만, 한국어 형태소 분석기 없이 PostgreSQL 내장 기능만으로 얻을 수 있는 현실적인 타협이다.
벡터 검색은 의미를 잡고, 키워드 검색은 고유명사를 잡는다. 캐릭터 이름이나 특정 장소명은 임베딩보다 정확한 토큰 매칭이 더 잘 찾는다.
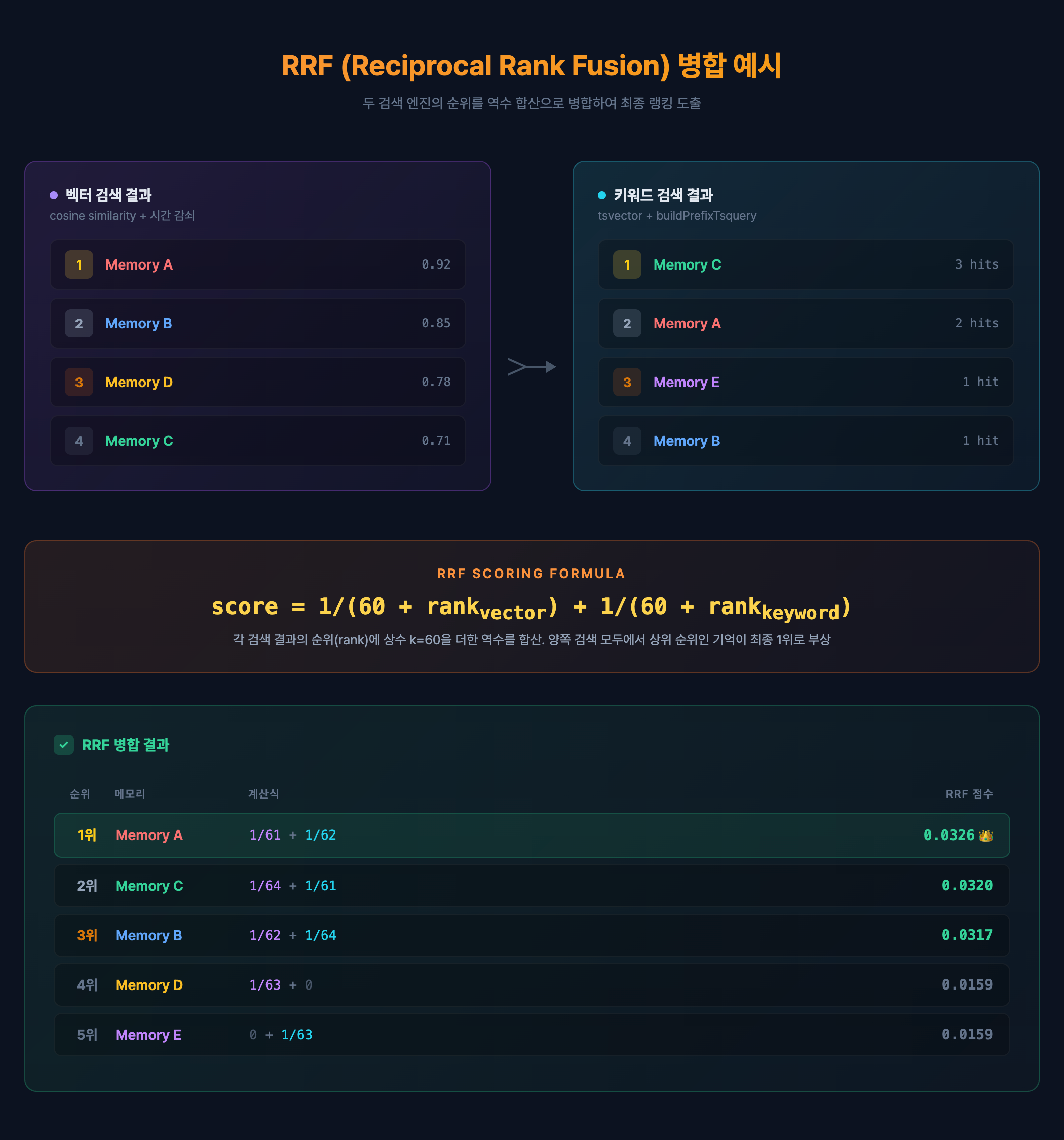
4. RRF (Reciprocal Rank Fusion) 병합
두 검색 결과를 어떻게 하나로 합치느냐가 핵심이다. 단순히 점수를 합산하면 스케일이 다른 두 점수(코사인 유사도 01 vs. ts_rank 0∞)를 비교하게 된다. RRF는 점수 대신 순위만 사용하므로 이 문제를 우회한다.
// memory-retrieval.service.ts — RRF 병합
static mergeByRRF(
vectorResults: MemoryResult[],
textResults: MemoryResult[],
limit: number,
k = 60, // RRF 상수
): MemoryResult[] {
const scoreMap = new Map<string, { score: number; item: MemoryResult }>();
// 벡터 검색 결과에 RRF 점수 부여
for (let i = 0; i < vectorResults.length; i++) {
const r = vectorResults[i];
scoreMap.set(r.id, { score: 1 / (k + i), item: r });
}
// 키워드 검색 결과의 RRF 점수를 누적 (중복 시 합산 → 양쪽 모두 상위면 점수 ↑)
for (let i = 0; i < textResults.length; i++) {
const r = textResults[i];
const existing = scoreMap.get(r.id);
if (existing) {
existing.score += 1 / (k + i); // 이미 있으면 합산
} else {
scoreMap.set(r.id, { score: 1 / (k + i), item: r });
}
}
return Array.from(scoreMap.values())
.sort((a, b) => b.score - a.score)
.slice(0, limit)
.map((e) => e.item);
}
RRF 공식은 score = Σ 1/(k + rank)다. k = 60은 학계에서 널리 쓰이는 기본값으로, 상위 순위에 과도한 가중치가 걸리지 않도록 완충 역할을 한다.
중복 처리가 자연스럽다는 점이 RRF의 강점이다. 벡터 검색 1위 + 키워드 검색 3위에 동시에 오른 기억은 1/60 + 1/63 ≈ 0.0325를 받고, 벡터 검색 1위에만 있는 기억은 1/60 ≈ 0.0167을 받는다. 양쪽에서 모두 관련 높다고 판단한 기억이 자연스럽게 상위로 올라간다.
5. 크로스 세션 메모리 (토크 모드)
스토리 모드와 토크 모드는 메모리 범위가 다르다.
| 스토리 모드 | 토크 모드 | |
|---|---|---|
| 메모리 범위 | 에피소드(세션) 단위 | 같은 방의 모든 세션 |
| 검색 대상 | 현재 세션 ID 1개 | 유저+방 조합의 세션 ID 전체 |
| 메모리 개수 | 8개 | 12개 |
토크 모드에서는 사용자가 같은 토크룸에 여러 번 입장할 수 있다. 세션이 달라져도 이전 대화 기억이 유지되어야 캐릭터의 일관성이 생긴다.
// memory-retrieval.service.ts — 토크 모드 크로스 세션 검색
async getRelevantMemories(
sessionId: string, query: string, limit = 8,
characterName?: string, isTalk?: boolean, userId?: string, talkRoomId?: string,
): Promise<MemoryResult[]> {
const effectiveLimit = isTalk ? 12 : limit;
// Talk 모드: 같은 유저+방의 모든 세션에서 메모리 검색
const sessionIds =
isTalk && userId && talkRoomId
? await this.getTalkSessionIds(userId, talkRoomId)
: [sessionId];
// ... 이후 하이브리드 검색 로직은 동일
}
getTalkSessionIds는 같은 userId + talkRoomId 조합의 모든 PlaySession ID를 가져온다. 이 ID 배열이 session_id = ANY($1::text[]) 조건으로 SQL에 전달되어, 여러 세션에 걸친 기억을 한 번에 검색한다.
스토리 모드에서 이렇게 하지 않는 이유는, 에피소드마다 맥락이 완전히 다르기 때문이다. EP.1의 기억이 EP.3에 부적절하게 주입되면 오히려 혼란을 준다.
6. 프롬프트에 기억 주입하기
검색된 기억은 시스템 프롬프트의 [과거 기억] 섹션으로 들어간다.
// prompt-builder.ts — 기억을 프롬프트에 주입
private buildMemoriesSection(): void {
if (!this.input.memories || this.input.memories.length === 0) return;
const memoryLines = this.input.memories.map((m) => {
const relTime = PromptBuilder.relativeTime(m.createdAt); // "2시간 전", "3일 전"
const involved =
m.involvedCharacters.length > 0
? ` [관련자: 플레이어, ${m.involvedCharacters.join(', ')}]`
: '';
let line = `- ${relTime}: ${m.summary}${involved}`;
if (m.keyDetails && m.keyDetails.length > 0) {
const details = m.keyDetails.map((d) => {
if (d.type === 'quote') {
return ` - 💬 ${d.speaker}: "${d.text}" (${d.context})`;
}
return ` - 🎬 ${d.actor}: ${d.text} (${d.context})`;
});
line += `\n${details.join('\n')}`;
}
return line;
});
// ...
}
각 기억에는 [관련자] 목록이 붙는다. 캐릭터별 지식 범위를 제한하기 위해서다. 캐릭터 A와 플레이어만 있었던 대화를 캐릭터 B가 알고 있으면 부자연스럽다. 프롬프트에 명시적으로 "관련자가 아닌 캐릭터는 해당 사건을 전혀 모른다"는 규칙을 넣어 이를 방지한다.
또 하나 중요한 것은 기억 한계 인식 규칙이다. 기억에 없는 사실을 AI가 지어내는 것(환각)을 방지하기 위해, 모르면 모른다고 솔직하게 반응하도록 프롬프트에서 강제한다.
"잘 기억이 안 나는데..." 같은 반응이 환각보다 훨씬 낫다.
7. 장기 메모리 압축
단기 메모리가 30개를 넘으면, 가장 오래된 20개를 하나의 장기 메모리로 압축한다. 핵심 사건과 관계 변화만 유지하고, 세부 대사는 삭제한다. 트랜잭션으로 장기 메모리 생성과 원본 삭제를 원자적으로 처리해 데이터 정합성을 보장한다.
// memory.service.ts — 장기 메모리 압축 (트랜잭션)
const [longTermMemory] = await this.prisma.$transaction([
this.prisma.sessionMemory.create({
data: {
sessionId,
type: 'long_term',
summary: this.encryption.encrypt(parsed.summary),
involvedCharacters: parsed.involvedCharacters,
affinitySnapshot: latestSnapshot ?? undefined,
messageRangeStart: oldest[0].messageRangeStart,
messageRangeEnd: oldest[oldest.length - 1].messageRangeEnd,
},
}),
this.prisma.sessionMemory.deleteMany({
where: { id: { in: oldestIds } },
}),
]);
이 압축은 fire-and-forget으로 실행되어 사용자 응답 지연에 영향을 주지 않는다. 메모리 테이블이 무한히 커지는 것을 방지하면서도, 오래된 기억의 핵심은 보존한다.
정리: 핵심 설계 판단
-
컨텍스트 윈도우는 제약이 아니라 설계 조건이다. 모든 대화를 넣을 수 없다는 전제에서 출발하면, "무엇을 기억할 것인가"라는 좋은 질문이 나온다.
-
Redis
SET NX는 가장 단순한 분산 락이다. 별도의 락 라이브러리 없이도, TTL + NX + try/finally로 충분히 안전한 락을 구현할 수 있다. -
벡터 검색과 키워드 검색은 상호 보완 관계다. 벡터는 의미적 유사성을, 키워드는 고유명사를 잘 잡는다. 한쪽만으로는 부족하다.
-
RRF는 스케일이 다른 점수를 병합하는 가장 깔끔한 방법이다. 순위만 사용하므로 정규화가 필요 없고, 구현도 20줄이면 끝난다.
-
한국어 전문검색은
simple토크나이저 + 접두사 매칭이 현실적 타협이다. 완벽하지 않지만, 형태소 분석기 의존성 없이 PostgreSQL만으로 동작한다. -
시간 감쇠는 벡터 검색에 필수다. 의미적으로 비슷한 기억이 여러 개일 때, 최근 기억에 자연스럽게 우선순위를 부여한다.
-
AI에게 "모르면 모른다고 해라"는 규칙은 환각 방지의 핵심이다. 기억 시스템이 아무리 좋아도, 검색 결과에 없는 내용을 지어내면 의미가 없다. 프롬프트 레벨에서 명시적으로 제한해야 한다.