도입
Plit은 AI 캐릭터와 대화하며 스토리를 경험하는 AI 채팅 플랫폼이다. 백엔드 스택으로 NestJS 11 + Prisma 7 + PostgreSQL 18 + pgvector를 선택했다. 2026년 3월 기준, 네 기술 모두 최신 메이저 버전이다.
Prisma 7의 driver adapter는 커넥션 풀링의 제약을 해소하고, NestJS 11의 DI 시스템은 14개 피처 모듈을 깔끔하게 관리해주며, pgvector는 별도 인프라 없이 PostgreSQL 안에서 시맨틱 검색을 가능하게 한다. 여기에 PostgreSQL 18의 비동기 I/O와 UUIDv7도 함께 활용한다.
하지만 "최신"에는 대가가 있다. ERD 제너레이터가 호환되지 않고, migrate dev가 pgvector 인덱스 때문에 오동작하고, 벡터 타입을 Prisma가 이해하지 못해 raw SQL을 섞어 써야 한다. 이 글은 개발 과정에서 발견한 호환성 이슈와 해결 전략을 다룬다.
핵심 1: Prisma 7 설정 — driver adapter와 생성 클라이언트
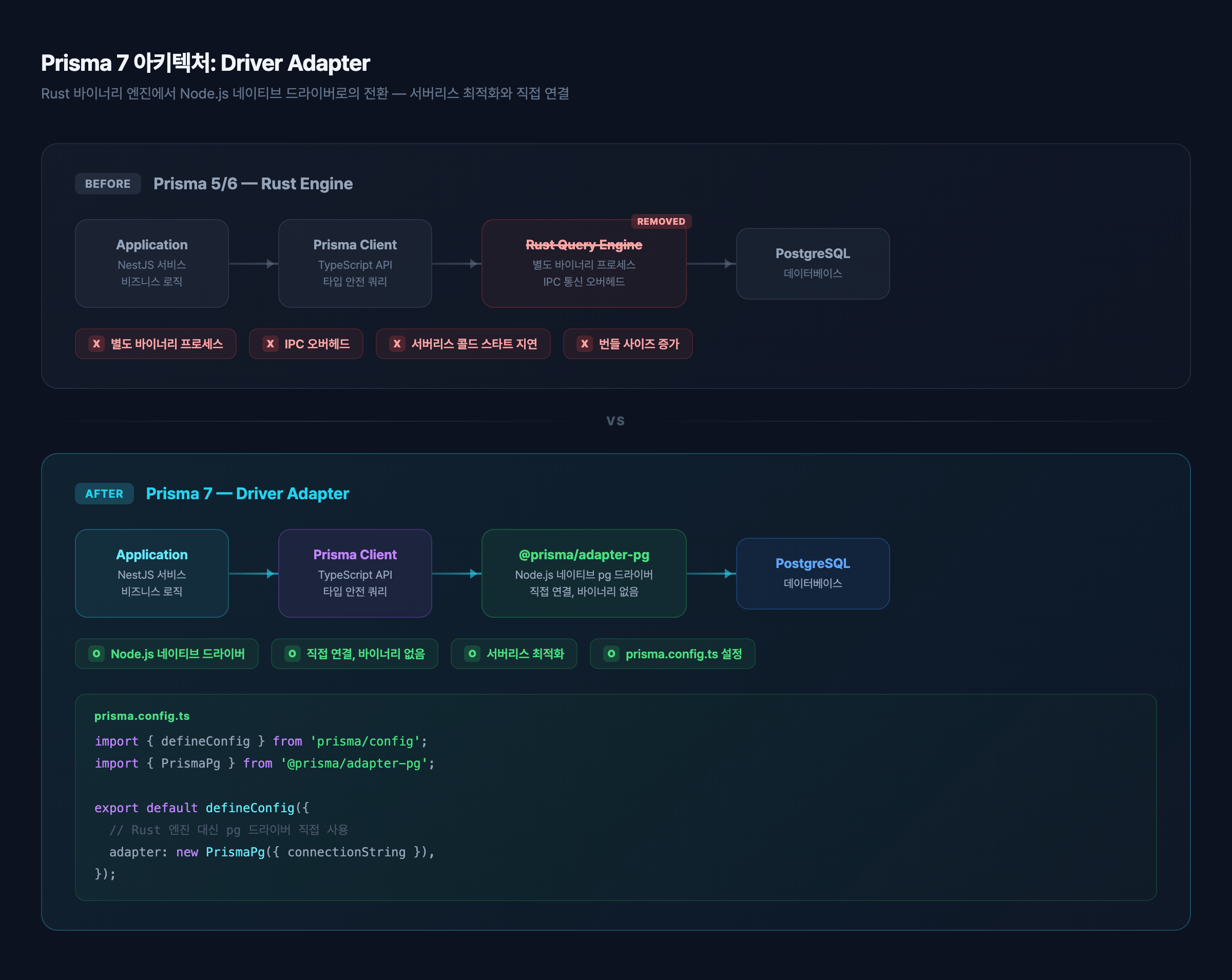
Prisma 7의 가장 큰 변화는 driver adapter다. Prisma 5까지는 Rust로 작성된 자체 엔진 바이너리가 DB 커넥션을 관리했다. Prisma 7은 이를 Node.js 네이티브 드라이버(pg, mysql2 등)로 대체한다. 서버리스 환경에서의 콜드 스타트 문제가 사라지고, 커넥션 풀링도 기존 드라이버 생태계를 그대로 활용할 수 있다.
Plit의 PrismaService에서 driver adapter를 설정하는 코드는 이렇다.
// src/common/prisma/prisma.service.ts
import { PrismaPg } from '@prisma/adapter-pg';
import { PrismaClient } from '../../generated/prisma/client.js';
@Injectable()
export class PrismaService
extends PrismaClient
implements OnModuleInit, OnModuleDestroy
{
constructor() {
super({
// Prisma 7: Node.js pg 드라이버를 직접 사용
adapter: new PrismaPg({
connectionString: process.env.DATABASE_URL,
}),
});
}
async onModuleInit() {
await this.$connect();
}
async onModuleDestroy() {
await this.$disconnect();
}
}
@prisma/adapter-pg가 pg 패키지를 래핑하여 Prisma에 전달한다. package.json에 pg가 명시적 의존성으로 들어가야 하는 점을 놓치기 쉽다. 기존에 pg를 직접 쓰지 않았다면 pnpm add pg @types/pg를 잊지 말 것.
생성 클라이언트의 위치도 달라졌다. schema.prisma에서 출력 경로를 지정한다.
// schema.prisma
generator client {
provider = "prisma-client"
output = "../src/generated/prisma"
moduleFormat = "cjs"
}
datasource db {
provider = "postgresql"
}
Prisma 7은 provider가 prisma-client-js에서 prisma-client로 바뀌었다. output으로 지정한 src/generated/prisma/는 .gitignore에 추가하고, 빌드 스크립트에서 prisma generate를 먼저 실행하도록 설정한다.
// package.json
{
"scripts": {
"build": "prisma generate && nest build"
}
}
Jest 호환성 문제도 있다. 생성 클라이언트의 import 경로가 .js 확장자를 포함하는데, Jest의 ts-jest는 이를 해석하지 못한다. moduleNameMapper로 .js를 제거해야 한다.
// package.json — Jest 설정
{
"jest": {
"moduleNameMapper": {
"^(\\.{1,2}/.*)\\.js$": "$1"
}
}
}
이 한 줄이 없으면 Cannot find module '../../generated/prisma/client.js' 에러가 발생한다. Prisma 7 마이그레이션 가이드에서도 언급하지만, 실제로 마주치면 원인을 찾기까지 시간이 걸린다.
핵심 2: migrate deploy vs migrate dev — pgvector가 만드는 드리프트
Plit의 make dev 스크립트는 prisma migrate deploy를 사용한다. prisma migrate dev가 아니다.
#!/usr/bin/env bash
# scripts/start_dev.sh
set -e
bash scripts/ensure_db.sh
bash scripts/ensure_redis.sh
cd backend
# deploy, not dev — pgvector 인덱스 드리프트 회피
npx prisma migrate deploy
pnpm run start:dev
migrate dev는 현재 DB 상태와 Prisma 스키마를 비교하여 **드리프트(drift)**를 감지한다. 문제는 pgvector의 HNSW 인덱스를 Prisma가 이해하지 못한다는 것이다.
실제 마이그레이션 SQL을 보면 이렇다.
-- 20260312100000_add_pgvector_embedding/migration.sql
CREATE EXTENSION IF NOT EXISTS vector;
ALTER TABLE "session_memories" ADD COLUMN "embedding" vector(512);
-- HNSW 인덱스 — 코사인 유사도 검색용
CREATE INDEX "session_memories_embedding_idx"
ON "session_memories" USING hnsw ("embedding" vector_cosine_ops);
이 마이그레이션은 정상적으로 적용된다. 하지만 이후 migrate dev를 실행하면, Prisma가 DB의 현재 스키마를 introspect하면서 vector(512) 타입과 hnsw 인덱스를 "알 수 없는 것"으로 판단한다. 드리프트가 감지되었으니 DB를 리셋하겠냐고 물어온다. 개발 중에 이 프롬프트에 yes를 누르면 데이터가 날아간다.
migrate deploy는 단순히 아직 적용되지 않은 마이그레이션 파일을 순서대로 실행할 뿐이다. 드리프트 감지를 하지 않으므로 pgvector 관련 문제가 발생하지 않는다.
정리하면:
- 개발 서버 시작:
prisma migrate deploy(드리프트 무시, 안전) - 새 마이그레이션 생성:
prisma migrate dev --create-only(SQL만 생성) - 마이그레이션 적용:
prisma migrate deploy(순서대로 실행)
이 워크플로우는 pgvector뿐 아니라 pg_trgm이나 tsvector 같은 Prisma가 네이티브로 지원하지 않는 PostgreSQL 확장을 사용할 때 모두 적용된다.
핵심 3: PostgreSQL 18로의 도약 — AIO, UUIDv7, Skip Scan
프로덕션 DB를 PostgreSQL 18로 올린 이유는 세 가지다. 모두 Plit의 사용 패턴에 직접적인 이점을 준다.
비동기 I/O(AIO) — pgvector 검색 성능의 게임 체인저
PostgreSQL 18의 가장 큰 아키텍처적 변화는 비동기 I/O 서브시스템이다. 기존에는 디스크 I/O가 동기식으로 처리되어 하나의 읽기 요청이 완료될 때까지 프로세스가 대기했다. PostgreSQL 18은 io_uring 등을 활용하여 다중 읽기 요청을 동시에 비동기로 처리한다.
Plit에서 이게 왜 중요한가? pgvector의 HNSW 인덱스 검색이 핵심이다. 매 사용자 메시지마다 512차원 벡터로 코사인 유사도 검색을 실행하는데, HNSW 인덱스는 그래프 구조를 탐색하면서 여러 디스크 페이지를 랜덤 읽기한다. AIO 덕분에 이 랜덤 읽기들이 동시에 처리되어, 특정 환경에서 순차 스캔 및 인덱스 조회 시 최대 3배의 읽기 성능 향상을 보인다. 채팅 응답의 TTFT(Time To First Token)에 직접 영향을 미치는 구간이라, 체감 효과가 크다.
UUIDv7 — 인덱스 파편화 해결
PostgreSQL 18은 uuidv7() 함수를 내장 지원한다. Plit의 모든 테이블은 UUID를 PK로 사용하는데, 기존 UUIDv4는 랜덤 생성이라 B-tree 인덱스가 파편화된다. 삽입할 때마다 인덱스의 임의 위치에 새 노드가 들어가기 때문이다.
UUIDv7은 타임스탬프 기반이라 시간순으로 정렬된다. 새로운 레코드가 항상 인덱스 끝에 추가되므로 페이지 분할이 줄고 쓰기 성능이 향상된다. Plit처럼 채팅 메시지와 세션 메모리가 시계열로 대량 생성되는 서비스에서 특히 유리하다.
-- PostgreSQL 18 — UUIDv7 네이티브 지원
-- 기존: gen_random_uuid() (v4, 랜덤)
-- 변경: uuidv7() (v7, 타임스탬프 정렬)
ALTER TABLE chat_messages
ALTER COLUMN id SET DEFAULT uuidv7();
현재 Prisma 스키마에서는 @default(uuid())로 v4를 사용 중이다. Prisma가 UUIDv7을 공식 지원하면 마이그레이션할 계획이지만, 그전에도 수동 SQL로 테이블별 default를 uuidv7()로 변경할 수 있다.
B-tree Skip Scan — 복합 인덱스 활용도 향상
다중 컬럼 인덱스에서 선행 컬럼 조건 없이도 후행 컬럼만으로 인덱스를 효율적으로 탐색할 수 있게 되었다. Plit의 session_memories 테이블은 (session_id, created_at) 복합 인덱스를 가지고 있는데, created_at만으로 조회할 때도 인덱스를 활용할 수 있어 불필요한 단일 컬럼 인덱스를 줄일 수 있다.
업그레이드 시 통계 유지
PostgreSQL 18 이전에는 pg_upgrade로 메이저 버전을 올리면 옵티마이저 통계가 초기화되어, 업그레이드 직후 쿼리 플랜이 최적이 아닌 상태로 실행되는 문제가 있었다. 18부터는 통계 정보가 그대로 이전되어, 프로덕션 업그레이드 직후의 성능 저하 위험이 사라졌다. 이 기능 덕분에 16 → 18 업그레이드를 비교적 안심하고 진행할 수 있었다.
핵심 4: NestJS 모듈 구조 — @Global() PrismaModule과 14개 피처 모듈
NestJS 11에서 Prisma를 사용하는 패턴은 간단하다. PrismaModule을 @Global()로 선언하면 모든 모듈에서 PrismaService를 주입받을 수 있다.
// src/common/prisma/prisma.module.ts
@Global()
@Module({
providers: [PrismaService],
exports: [PrismaService],
})
export class PrismaModule {}
AppModule에서 한 번만 import하면 된다. 14개 피처 모듈이 각각 PrismaModule을 import할 필요가 없다.
// src/app.module.ts — 19개 모듈 등록
@Module({
imports: [
SentryModule.forRoot(),
ConfigModule.forRoot({ isGlobal: true }),
PrismaModule, // @Global — 전체 앱에서 PrismaService 주입 가능
RedisModule, // @Global — 전체 앱에서 RedisService 주입 가능
RateLimitModule,
EncryptionModule,
StorageModule,
AiClientModule,
AuthModule,
StoriesModule,
SessionsModule,
ChatModule,
CharactersModule,
// ... 나머지 피처 모듈들
],
})
export class AppModule implements NestModule {
configure(consumer: MiddlewareConsumer) {
consumer.apply(IpRateLimitMiddleware).forRoutes('*');
}
}
모든 서비스는 생성자 주입으로 PrismaService를 받는다. 트랜잭션이 필요한 경우 prisma.$transaction()을 사용한다. Plit에서 트랜잭션은 주로 재화 관련 로직에서 쓰인다. 젬 차감과 기록 생성이 원자적이어야 하기 때문이다.
// src/gems/gems.service.ts — 인터랙티브 트랜잭션
async consume(userId: string, reason: GemTransactionReason) {
const cost = GEM_COST[reason];
return this.prisma.$transaction(async (tx) => {
// 원자적 잔액 차감 — race condition 방지를 위해 raw SQL 사용
const result = await tx.$queryRawUnsafe<{ balance: number }[]>(
'UPDATE gem_wallets SET balance = balance - $1, updated_at = NOW() WHERE user_id = $2 AND balance >= $1 RETURNING balance',
cost,
userId,
);
if (result.length === 0) {
throw new HttpException('젬이 부족합니다', HttpStatus.PAYMENT_REQUIRED);
}
// 거래 기록 생성
await tx.gemTransaction.create({
data: {
walletId: wallet.id,
type: GemTransactionType.CONSUME,
amount: -cost,
balanceAfter: result[0].balance,
reason,
},
});
return { balance: result[0].balance };
});
}
여기서 주목할 점은 트랜잭션 안에서 raw SQL과 Prisma ORM을 섞어 쓴다는 것이다. tx.$queryRawUnsafe로 원자적 잔액 차감(WHERE 조건에 balance >= $1 포함)을 하고, tx.gemTransaction.create로 ORM 기반 레코드 생성을 한다. Prisma 7의 인터랙티브 트랜잭션은 이런 혼합 패턴을 자연스럽게 지원한다.
메모리 압축 같은 배치 작업에서는 배열 기반 트랜잭션도 사용한다.
// src/ai-pipeline/services/memory.service.ts — 배열 트랜잭션
const [longTermMemory] = await this.prisma.$transaction([
this.prisma.sessionMemory.create({
data: { sessionId, type: 'long_term', summary: encryptedSummary, /* ... */ },
}),
this.prisma.sessionMemory.deleteMany({
where: { id: { in: oldestIds } },
}),
]);
장기 메모리 생성과 원본 삭제를 하나의 트랜잭션으로 묶는다. 인터랙티브 트랜잭션보다 가볍고, 읽기/쓰기가 독립적인 경우에 적합하다.
핵심 5: pgvector와 raw SQL의 공존
Prisma는 PostgreSQL의 vector 타입을 네이티브로 지원하지 않는다. 스키마에서는 Unsupported로 선언한다.
// schema.prisma — pgvector 컬럼 선언
model SessionMemory {
id String @id @default(uuid())
sessionId String @map("session_id")
summary String @db.Text
embedding Unsupported("vector(512)")?
searchVector Unsupported("tsvector")? @map("search_vector")
// ...
@@map("session_memories")
}
Unsupported 타입은 Prisma가 해당 컬럼을 마이그레이션에서 관리하지 않겠다는 의미다. 실제 컬럼 생성과 인덱스 설정은 수동 마이그레이션 SQL로 처리한다. findMany나 create에서 이 필드는 읽기/쓰기가 불가능하다.
따라서 벡터 관련 작업은 모두 raw SQL이다.
임베딩 저장 — 메모리 생성 후 Voyage AI로 임베딩을 얻어 vector(512) 컬럼에 저장한다.
// src/ai-pipeline/services/memory.service.ts — 벡터 임베딩 저장
const embedding = await this.generateEmbedding(parsed.summary);
if (embedding) {
const vectorStr = `[${embedding.join(',')}]`; // "[0.123, -0.456, ...]"
await this.prisma.$executeRawUnsafe(
`UPDATE session_memories SET embedding = $1::vector WHERE id = $2`,
vectorStr,
memory.id,
);
}
코사인 유사도 검색 — pgvector의 <=> 연산자를 사용한다. 시간 가중치를 적용하여 최신 기억에 더 높은 점수를 부여한다. PostgreSQL 18의 AIO 덕분에 HNSW 인덱스의 랜덤 읽기가 비동기로 처리되어, 이 쿼리의 응답 시간이 16 대비 체감할 수 있을 정도로 빨라졌다.
// src/ai-pipeline/services/memory-retrieval.service.ts — 시맨틱 검색
private async getVectorResults(
sessionIds: string[],
vectorStr: string,
limit: number,
characterName?: string,
): Promise<MemoryResult[]> {
// 코사인 유사도 * 시간 감쇠 (반감기 1일)
const scoreSql =
`(1 - (embedding <=> $2::vector)) * ` +
`EXP(-0.693 * EXTRACT(EPOCH FROM (NOW() - created_at)) / 86400.0)`;
const rows: MemoryResult[] = await this.prisma.$queryRawUnsafe(
`SELECT id, summary,
involved_characters AS "involvedCharacters",
key_details AS "keyDetails",
created_at AS "createdAt"
FROM session_memories
WHERE session_id = ANY($1::text[])
ORDER BY ${scoreSql} DESC
LIMIT $3`,
sessionIds,
vectorStr,
limit,
);
return this.decryptMemoryResults(rows);
}
<=> 연산자는 코사인 거리를 반환한다 (0 = 동일, 2 = 정반대). 1 - distance로 유사도로 변환하고, 시간에 따른 지수 감쇠를 곱한다. 하루가 지나면 점수가 절반으로 줄어들어, 오래된 기억보다 최근 기억이 우선된다.
하이브리드 검색 — 벡터 검색(의미)과 tsvector 검색(키워드)을 **Reciprocal Rank Fusion(RRF)**으로 합친다.
// RRF 병합 — 두 랭킹 리스트를 하나로
static mergeByRRF(
vectorResults: MemoryResult[],
textResults: MemoryResult[],
limit: number,
k = 60, // RRF 상수
): MemoryResult[] {
const scoreMap = new Map<string, { score: number; item: MemoryResult }>();
for (let i = 0; i < vectorResults.length; i++) {
scoreMap.set(vectorResults[i].id, {
score: 1 / (k + i),
item: vectorResults[i],
});
}
for (let i = 0; i < textResults.length; i++) {
const existing = scoreMap.get(textResults[i].id);
if (existing) {
existing.score += 1 / (k + i); // 양쪽에 등장하면 점수 합산
} else {
scoreMap.set(textResults[i].id, {
score: 1 / (k + i),
item: textResults[i],
});
}
}
return Array.from(scoreMap.values())
.sort((a, b) => b.score - a.score)
.slice(0, limit)
.map((e) => e.item);
}
벡터 검색은 "비슷한 맥락"을, tsvector 검색은 "정확한 키워드"를 잡아낸다. RRF가 두 결과를 공정하게 병합한다.

핵심 6: 스키마 설계 패턴 — 17개 테이블, 12개 enum
Plit의 스키마는 17개 테이블과 12개 enum으로 구성된다. 몇 가지 반복적으로 사용한 패턴을 정리한다.
JSONB로 유연한 상태 관리. 구조가 자주 바뀌는 데이터는 JSONB 컬럼에 저장한다. PostgreSQL 17에서 도입된 JSON_TABLE로 JSONB를 관계형 테이블처럼 쿼리할 수 있게 되었는데, 향후 복잡한 분석 쿼리에 활용할 수 있다.
model Character {
persona Json? // { personality, speaking_style, speech_examples[] }
identity Json? // { backstory, core_traits[], motivation, flaw, archetype }
emotionConfig Json? @map("emotion_config")
safety Json? // { never_do[], always_do[], escalation_response }
}
model PlaySession {
stateJson Json? @map("state_json") // 이벤트 진행 상태, 플래그 등
}
model ChatMessage {
affinitySnapshot Json? @map("affinity_snapshot") // 되감기용 호감도 스냅샷
}
Character.persona는 AI 프롬프트에 직접 주입되는 구조화 데이터다. 필드가 추가되어도 마이그레이션이 필요 없다. ChatMessage.affinitySnapshot은 되감기 기능을 위한 스냅샷 — 각 메시지 시점의 호감도를 기록해두면, 되감기 시 해당 시점으로 복원할 수 있다.
Enum 중심의 타입 안전성. 문자열 대신 enum을 사용하면 Prisma 클라이언트가 타입을 체크한다.
enum CharacterRole {
MAIN_LOVE
SUB_LOVE
RIVAL
FRIEND
ANTAGONIST
NARRATOR
SUPPORT
}
enum GemTransactionReason {
PURCHASE
SUBSCRIPTION_MONTHLY
REWIND
ENERGY_CHARGE
AFFINITY_BOOST
STORY_UNLOCK
// ... 14개 사유
}
TypeScript에서 GemTransactionReason.ENERGY_CHARGE처럼 사용하면 오타가 컴파일 타임에 잡힌다.
@map으로 snake_case 매핑. TypeScript는 camelCase, PostgreSQL은 snake_case가 관례다. Prisma의 @map으로 양쪽 관례를 모두 유지한다.
model StoryCharacter {
storyId String @map("story_id")
characterId String @map("character_id")
initialAffinity Int @default(15) @map("initial_affinity")
@@map("story_characters")
}
TypeScript 코드에서는 storyCharacter.initialAffinity, SQL 쿼리에서는 initial_affinity로 접근한다. raw SQL과 ORM을 섞어 쓰는 프로젝트에서 이 일관성이 중요하다.
N:M 연결 테이블의 맥락 분리. 캐릭터가 독립 엔티티이므로, 특정 스토리에서의 역할과 캐릭터 원본을 분리해야 한다.
model StoryCharacter {
// 이 스토리에서의 역할
role CharacterRole
initialAffinity Int @default(15)
storyContext Json? // { secret, arc, relationships[] }
affinityThresholds Json? // { cold, wary, neutral, warm, intimate }
@@unique([storyId, characterId])
}
같은 캐릭터가 스토리 A에서는 MAIN_LOVE, 스토리 B에서는 RIVAL이 될 수 있다. 연결 테이블이 맥락을 담당하고, 캐릭터 원본은 불변이다.
정리
Prisma 7 + NestJS 11 + PostgreSQL 18 + pgvector를 실전에 적용하며 확인한 핵심 판단이다.
-
Prisma 7의 driver adapter는 실전에서 안정적이다.
@prisma/adapter-pg로pg드라이버를 직접 사용하면 Rust 엔진 바이너리가 사라지고, 커넥션 관리가 투명해진다. 다만pg를 명시적 의존성으로 추가하는 것과, Jest의moduleNameMapper설정을 잊지 말 것. -
pgvector를 쓰면
migrate deploy를 기본으로 삼아라.migrate dev의 드리프트 감지가 pgvector, tsvector 등 Prisma가 이해하지 못하는 타입과 충돌한다. 새 마이그레이션은--create-only로 생성하고, 적용은deploy로 분리하는 워크플로우가 안전하다. -
PostgreSQL 18의 AIO는 pgvector 검색에 실질적인 이점을 준다. HNSW 인덱스의 랜덤 I/O가 비동기로 처리되어 벡터 검색 응답 시간이 개선된다. UUIDv7은 시계열 데이터의 인덱스 파편화를 해결하고, Skip Scan은 복합 인덱스의 활용도를 높인다. 최신 버전 업그레이드의 ROI가 명확한 케이스다.
-
Unsupported타입은 "Prisma의 영역 밖"이라는 선언이다. 벡터 컬럼의 생성, 인덱싱, 검색은 모두 수동 SQL로 처리해야 한다. 이 경계를 명확히 인식하면 ORM과 raw SQL의 혼용이 자연스러워진다. -
@Global()모듈은 인프라 서비스에만 제한하라. Plit은 PrismaModule, RedisModule 등 인프라 수준의 모듈만@Global()로 선언한다. 도메인 서비스까지 글로벌로 만들면 의존성 추적이 불가능해진다. -
트랜잭션 안에서 raw SQL과 ORM을 섞어 써도 된다. 잔액 차감 같은 race condition 민감한 연산은
$queryRawUnsafe의WHERE balance >= $1로 처리하고, 기록 생성은 ORM의 타입 안전성을 활용한다. Prisma 7의 인터랙티브 트랜잭션이 이 패턴을 지원한다. -
JSONB + Enum + @map — 이 세 가지가 Prisma 스키마의 핵심 도구다. 유연한 데이터는 JSONB, 타입 안전성은 enum, 네이밍 관례 차이는
@map으로 해결한다. PostgreSQL 17의JSON_TABLE과 18의 가상 생성 컬럼이 JSONB의 활용 범위를 더 넓혀줄 것이다.