도입
플릿(Plit)은 AI 캐릭터와 자연어로 대화하며 스토리, 토크룸, 캐릭터 챗 세 가지 모드를 경험하는 AI 채팅 플랫폼이다. 스토리 모드에서는 플롯 기반의 분기형 스토리를, 토크룸에서는 테마 기반의 자유 대화를, 캐릭터 챗에서는 1:1 관계형 대화를 제공한다.
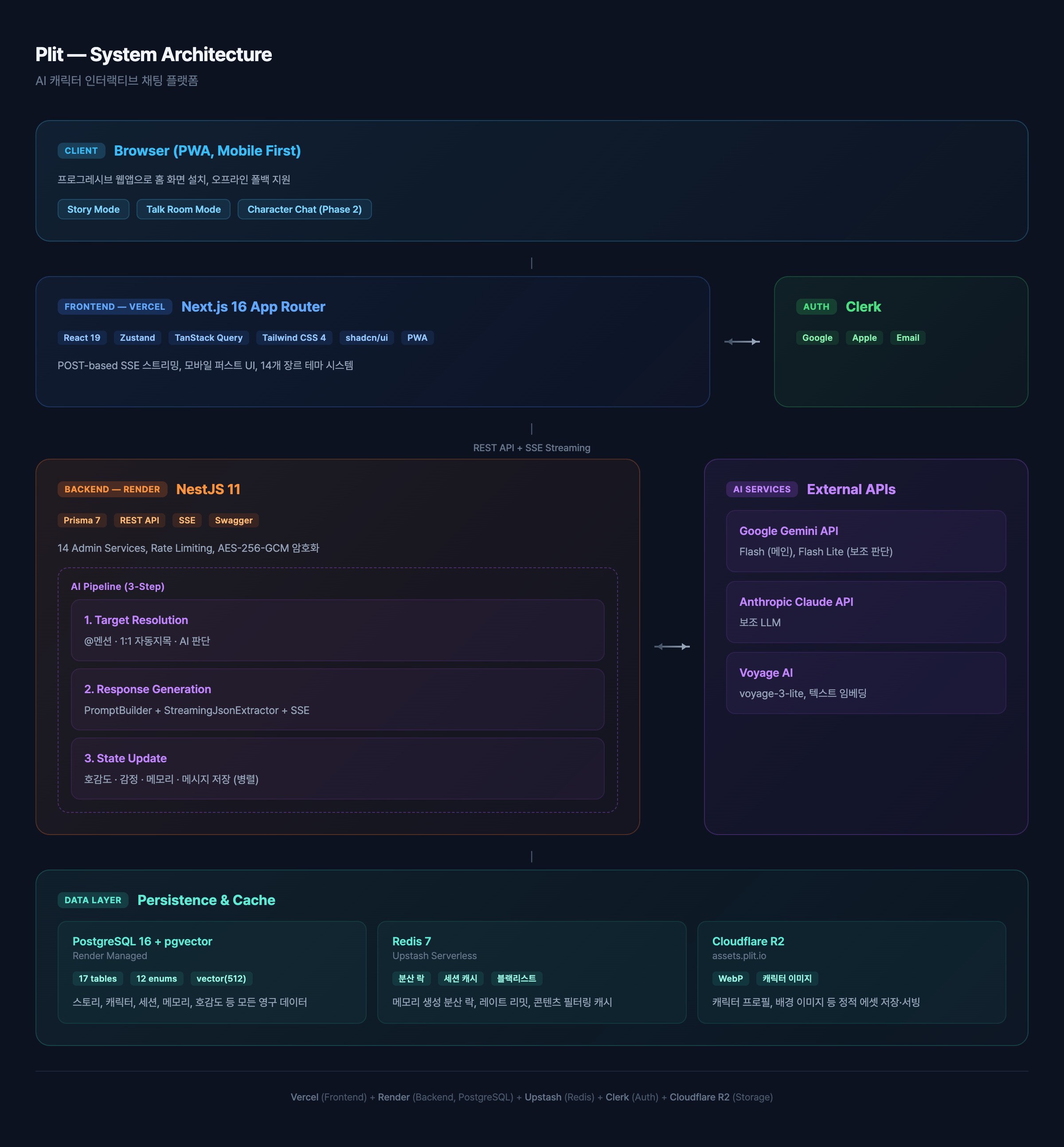
이 프로젝트의 아키텍처는 **운영 가능성(operability)**을 중심으로 설계했다. 기획부터 인프라까지 전 영역을 빠르게 순회해야 하는 환경에서, 매 선택의 기준은 "이 구조가 최소 인원으로 안정적으로 운영 가능한가?"였다. 확장 가능하되 과도하지 않은 아키텍처를 지향한다.
이 글에서는 플릿의 전체 시스템 아키텍처를 다룬다. 인프라 선택, 모노레포 구조, 데이터베이스 설계, 백엔드 모듈 구조, 프론트엔드 아키텍처까지 — 각 선택에서 어떤 트레이드오프를 거쳐 현재 구조에 도달했는지를 정리한다.
핵심 1: 인프라 선택 — 관리형 서비스 조합
인프라를 선택할 때 핵심 기준은 세 가지다: 운영 부담 최소화, 비용 예측 가능성, 스케일업 여지.
| 서비스 | 역할 | 선택 이유 |
|---|---|---|
| Vercel | 프론트엔드 호스팅·CDN·SSR | Next.js 네이티브 지원, Zero-config 배포 |
| Render | 백엔드 API 서버 | render.yaml 하나로 설정 완료, auto-scaling |
| Neon | PostgreSQL 18 + pgvector | 서버리스, 브랜칭 지원, 연결 풀링 내장 |
| Upstash | Redis (캐시·분산 락·설정) | 서버리스, REST 프로토콜 지원, 사용량 기반 과금 |
| Clerk | 인증 (OAuth + JWT) | 구글·애플·이메일 로그인을 코드 수십 줄로 구현 |
| Cloudflare R2 | 이미지 스토리지 | S3 호환 API, egress 비용 없음 |
핵심 원칙: 직접 관리해야 하는 인프라를 최소화한다. DB 백업, SSL 인증서 갱신, 인증 보안 패치 — 이런 것들을 관리형 서비스에 위임하면 제품 개발에 집중할 수 있다.
특히 Clerk의 선택이 개발 시간을 크게 단축했다. 구글·애플 OAuth, JWT 발급·검증, 세션 관리를 직접 구현했다면 최소 1-2주가 더 필요했을 것이다. 프론트엔드에서는 ClerkProvider로 감싸고, 백엔드에서는 @clerk/backend의 verifyToken()으로 JWT를 검증하는 것만으로 인증 전체가 해결된다.
로컬 개발 환경은 Docker Compose로 PostgreSQL과 Redis만 띄운다:
# docker-compose.yml
services:
postgres:
image: pgvector/pgvector:pg18 # pgvector 확장 내장
container_name: plit-postgres
environment:
POSTGRES_DB: plit
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
ports:
- '5432:5432'
redis:
image: redis:7-alpine
container_name: plit-redis
command: redis-server --appendonly yes
ports:
- '6379:6379'
로컬과 프로덕션의 차이는 환경변수뿐이다. DATABASE_URL이 로컬 Docker를 가리키느냐 Neon을 가리키느냐의 차이.
핵심 2: 모노레포 구조 — 도구 없는 모노레포
plit/
├── backend/ # NestJS 11 (port 3001)
├── frontend/ # Next.js 16 (port 3000)
├── docs/ # SRS, 시스템 디자인, 가이드
├── scripts/ # 인프라 스크립트
├── docker-compose.yml
└── Makefile # 통합 명령어
Turborepo나 Nx 같은 모노레포 도구를 쓰지 않는다. 각 디렉토리에서 독립적으로 pnpm 명령어를 실행하는 구조다.
이유는 단순하다. 현재 규모에서 모노레포 도구는 오버헤드다. 공유 패키지도 없고, 빌드 캐시 최적화가 필요할 만큼 빌드가 느리지도 않다. Makefile로 자주 쓰는 명령어를 묶는 것으로 충분하다:
# Makefile (주요 명령어)
make setup # Docker 컨테이너 + 의존성 + 마이그레이션 + 시드
make dev # 백엔드 dev 서버 시작
make dump-seed # DB → seed 파일 내보내기
make reset-db # Drop → create → migrate → seed
백엔드와 프론트엔드가 같은 저장소에 있으면 좋은 점은 스키마 변경의 영향 범위를 한눈에 파악할 수 있다는 것이다. Prisma 스키마를 수정하면 백엔드 DTO와 프론트엔드 타입을 같은 PR에서 함께 업데이트할 수 있다.
핵심 3: 데이터베이스 설계 — 캐릭터는 독립 엔티티
17개 테이블, 12개 Enum으로 구성된 스키마에서 가장 중요한 설계 결정은 캐릭터를 독립 엔티티로 분리한 것이다.
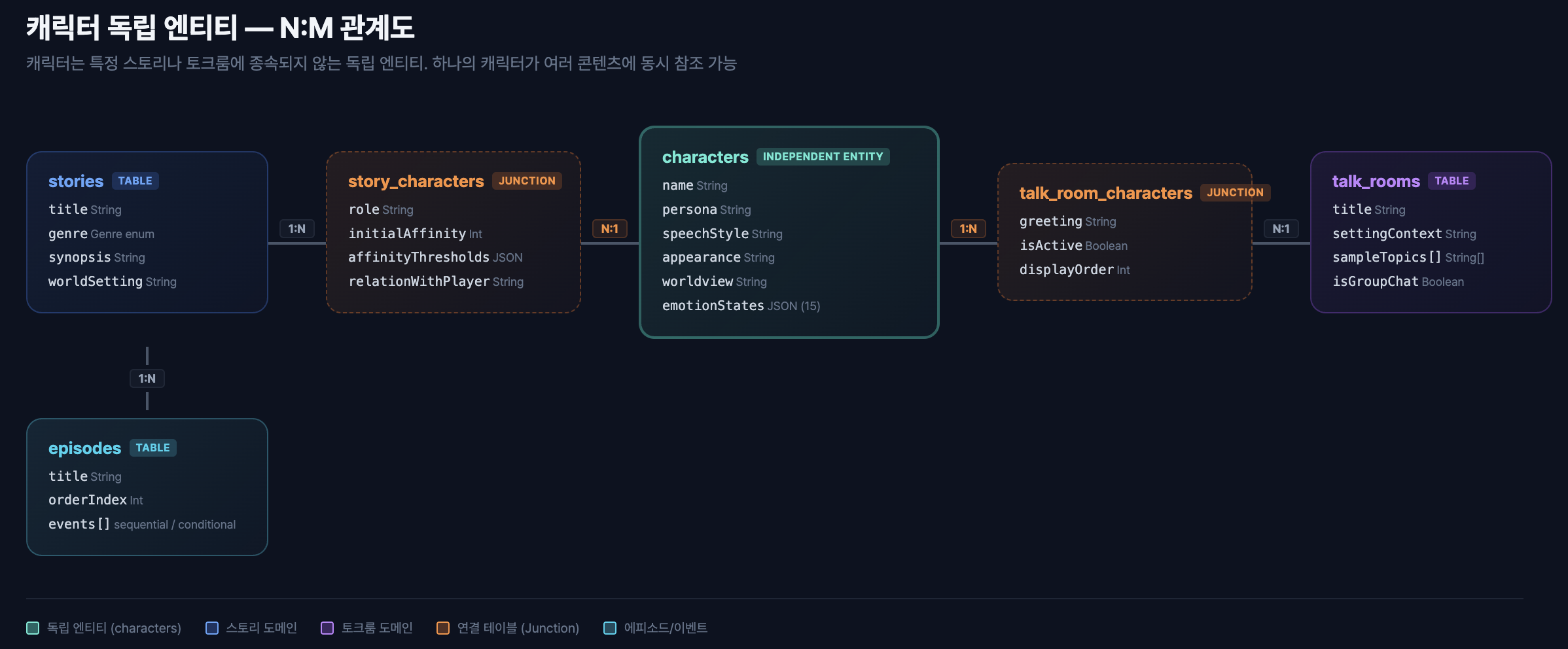
캐릭터 독립성 설계
처음에는 캐릭터를 스토리 안에 포함시키는 단순한 구조를 생각했다. 하지만 같은 캐릭터가 스토리 A, 스토리 B(시즌 2), 토크룸 C에 동시에 등장해야 하는 요구사항이 있었다. 캐릭터 자체가 IP이므로, 특정 콘텐츠에 종속되면 안 된다.
// 캐릭터 — 독립 엔티티. 페르소나, 말투, 감정 체계의 원본
model Character {
id String @id @default(uuid())
name String
persona Json? // { personality, speaking_style, speech_examples[] }
identity Json? // { backstory, core_traits[], motivation, flaw }
emotionConfig Json? // { default, emotional_range[], triggers[] }
// N:M 관계 — 여러 스토리·토크룸에 참조 가능
storyLinks StoryCharacter[]
talkRoomLinks TalkRoomCharacter[]
}
// 연결 테이블 — 스토리 안에서의 역할·초기 호감도는 여기서 관리
model StoryCharacter {
storyId String @map("story_id")
characterId String @map("character_id")
role CharacterRole // MAIN_LOVE, RIVAL, FRIEND ...
initialAffinity Int @default(15)
storyContext Json? // { secret, arc, relationships[] }
@@unique([storyId, characterId])
}
캐릭터 원본(페르소나, 말투)은 characters 테이블에, 맥락(스토리에서의 역할, 초기 호감도)은 story_characters 연결 테이블에 저장한다. 이 분리 덕분에 하나의 캐릭터가 스토리에서는 라이벌이면서, 토크룸에서는 친근한 상담자 역할을 수행할 수 있다.
JSONB 활용: 유연한 상태 저장
정형화하기 어려운 데이터에는 JSONB를 적극 활용했다:
PlaySession.stateJson: 현재 이벤트 ID, 스토리 플래그, 진행 상태 등 세션 런타임 상태ChatMessage.affinitySnapshot: 메시지 시점의 호감도 스냅샷 (되감기 기능에 사용)Event.triggerCondition: 이벤트 트리거 조건 ({ type: 'affinity_gte', character_id, value })Character.persona: AI 프롬프트에 주입되는 구조화된 페르소나 데이터
pgvector: 시맨틱 메모리 검색
SessionMemory 테이블에 vector(512) 타입의 임베딩 컬럼을 두고, Voyage AI(voyage-3-lite)로 생성한 벡터를 저장한다. 대화 5회마다 AI가 기억을 요약하고, 이 요약의 임베딩을 저장해두면 다음 대화에서 관련 기억을 시맨틱 검색으로 가져올 수 있다.
model SessionMemory {
summary String @db.Text
embedding Unsupported("vector(512)")? // Voyage AI 임베딩
keyDetails Json? @db.JsonB
@@map("session_memories")
}
Prisma에서 pgvector는
Unsupported타입으로 선언한다. Raw SQL로 벡터 연산을 수행해야 하지만, 나머지 CRUD는 Prisma가 처리하므로 큰 불편은 없다.
핵심 4: 백엔드 모듈 구조 — God Service의 실패와 개선
NestJS 11 백엔드는 표준 모듈 패턴(Controller → Service → Prisma)을 따른다.
backend/src/
├── admin/ # 관리자 CRUD (13개 서비스로 분리)
├── ai-pipeline/ # 3단계 AI 처리 파이프라인
├── auth/ # Clerk JWT 검증
├── chat/ # 채팅 메시지 + SSE 스트리밍
├── characters/ # 캐릭터 조회·이미지 생성
├── content-safety/ # 블랙리스트 필터링
├── energy/ # 행동력 관리
├── gems/ # 젬 지갑·거래
├── sessions/ # 플레이 세션 관리
├── stories/ # 스토리 조회
├── subscriptions/ # 구독 관리
├── common/ # 공유 유틸 (storage, crypto, testing)
└── app.module.ts
Anti-Pattern 경험: AdminService 분리
초기에 AdminService 하나에 스토리 CRUD, 캐릭터 CRUD, 세션 관리, 콘텐츠 안전 로직을 모두 넣었다. 200줄이 넘어가자 어떤 메서드가 어디에 있는지 찾기 어려워졌고, 한 도메인을 수정할 때 다른 도메인의 import가 깨지는 일이 반복됐다.
God Service를 13개 도메인별 서비스로 분리했다:
admin/
├── admin.service.ts # 대시보드 통계만 담당
├── admin-story.service.ts # Story + Episode + Event CRUD
├── admin-character.service.ts # Character CRUD
├── admin-talk-room.service.ts # TalkRoom CRUD
├── admin-session.service.ts # Session 조회·삭제
├── admin-user.service.ts # User 목록·역할 변경
├── admin-gem.service.ts # 젬 트랜잭션·잔액
├── admin-content-safety.service.ts # 블랙리스트·안전 로그
├── admin-content-io.service.ts # 콘텐츠 Export/Import
├── admin-subscription.service.ts # 구독·프로모 코드
├── admin-image.service.ts # 이미지 업로드
├── admin-ai-generation.service.ts # AI 스토리·캐릭터 생성
└── admin-user-lookup.service.ts # Clerk 유저 조회 (공유 헬퍼)
규칙은 단순하다: 하나의 서비스 파일이 200줄을 넘으면 분리를 검토한다. Controller는 하나(AdminController)를 유지하되, 내부에서 도메인별 서비스를 주입받아 위임한다.
글로벌 모듈
PrismaModule과 RedisModule을 @Global()로 등록하여 모든 모듈에서 import 없이 주입받을 수 있게 했다. Prisma 7의 @prisma/adapter-pg 드라이버 어댑터를 사용하며, 생성된 클라이언트는 src/generated/prisma/에 위치한다(gitignore 대상).
핵심 5: 프론트엔드 아키텍처 — 모바일 퍼스트 PWA
Next.js 16 App Router + React 19 + React Compiler 조합이다.
상태 관리 전략
상태를 서버 상태와 클라이언트 상태로 명확히 분리한다:
| 구분 | 도구 | 용도 |
|---|---|---|
| 서버 상태 | TanStack Query | API 데이터 페칭·캐싱·무효화 |
| 채팅 상태 | Zustand (chatStore) | 메시지, SSE 스트리밍, 호감도, 게임 상태 |
| UI 상태 | Zustand (chatUIStore) | 모달 토글, 스크롤 위치, 자동 모드 |
chatStore와 chatUIStore를 분리한 이유가 있다. 채팅 로직(메시지 전송, SSE 처리, 되감기)은 비동기 사이드 이펙트가 많고, UI 상태(모달 열림/닫힘, 선택된 캐릭터)는 순수한 setter다. 이 둘을 한 store에 넣으면 불필요한 리렌더링이 발생한다.
SSE 스트리밍: POST 기반
브라우저 내장 EventSource는 GET만 지원하므로, 메시지 본문을 보내야 하는 채팅에는 쓸 수 없다. fetch + ReadableStream으로 POST 기반 SSE를 직접 구현했다:
// lib/sse.ts — POST 기반 SSE 클라이언트 (핵심 구조)
const response = await fetch(url, {
method: 'POST',
headers: { 'Content-Type': 'application/json', Authorization: `Bearer ${token}` },
body: JSON.stringify(payload),
});
const reader = response.body!.getReader();
const decoder = new TextDecoder();
// event: / data: 라인을 파싱하여 콜백으로 전달
while (true) {
const { done, value } = await reader.read();
if (done) break;
// SSE 이벤트 파싱 로직...
}
모바일 퍼스트
모든 UI는 모바일 뷰포트를 최우선으로 설계한다. dvh 단위로 뷰포트 높이를 계산하고, iOS safe area를 고려한 패딩을 적용한다. PWA(next-pwa)로 홈 화면 설치와 오프라인 폴백을 지원하며, Flutter 네이티브 앱이 나오기 전까지 모바일 사용자 경험의 주력 채널 역할을 한다.
기술 스택 정리
| 영역 | 기술 | 버전/비고 |
|---|---|---|
| 프론트엔드 | Next.js (App Router) | 16, React 19, React Compiler |
| 백엔드 | NestJS | 11 |
| ORM | Prisma | 7.x, @prisma/adapter-pg 드라이버 어댑터 |
| 데이터베이스 | PostgreSQL + pgvector | 18, 시맨틱 메모리 검색 |
| 캐시/락 | Redis (Upstash) | 7, AI 설정·분산 락·세션 캐시 |
| 인증 | Clerk | 구글·애플·이메일 OAuth + JWT |
| AI (메인) | Google Gemini | Flash, Flash Lite |
| AI (보조) | Anthropic Claude | Sonnet, Haiku |
| 임베딩 | Voyage AI | voyage-3-lite, vector(512) |
| 스토리지 | Cloudflare R2 | S3 호환, WebP 이미지 |
| 호스팅 | Vercel + Render | 프론트/백 분리 배포 |
| UI | shadcn + Tailwind CSS 4 | @base-ui/react 프리미티브 |
| 상태 관리 | Zustand + TanStack Query | 클라이언트/서버 상태 분리 |
| 애니메이션 | Framer Motion | 온보딩, 페이지 전환 |
| 모니터링 | Sentry | 프론트엔드 + 백엔드 |
| 패키지 매니저 | pnpm | Node.js v24+ |
정리: 아키텍처 핵심 판단 7가지
-
관리형 서비스를 적극 활용한다. 인증(Clerk), DB(Neon), 캐시(Upstash), 스토리지(R2) — 직접 운영할 인프라를 최소화해야 제품 개발에 집중할 수 있다.
-
모노레포 도구는 필요할 때 도입한다. 현재 규모에서 Turborepo는 오버헤드다. 같은 저장소에 넣되, 각 디렉토리에서 독립 실행하는 것만으로 충분하다.
-
엔티티 독립성을 초기에 설계한다. 캐릭터를 독립 엔티티로 분리한 결정은 이후 토크룸, 캐릭터 챗 모드 확장에서 큰 효과를 발휘했다. 연결 테이블의 비용보다 확장성의 이득이 크다.
-
God Service가 되기 전에 분리한다. 200줄 규칙을 두고, 넘기 전에 도메인별로 쪼갠다. 나중에 분리하면 import 정리만 반나절이다.
-
JSONB는 스키마 변경 비용을 줄여준다.
stateJson,affinitySnapshot,triggerCondition처럼 구조가 자주 바뀌는 데이터는 JSONB로 유연하게 대응할 수 있다. 단, 쿼리 성능이 중요한 필드는 정규 컬럼으로 분리한다. -
서버 상태와 클라이언트 상태를 명확히 분리한다. TanStack Query(서버)와 Zustand(클라이언트)의 역할 경계를 명확히 하면, "이 데이터를 어디서 관리하지?"라는 고민이 사라진다.
-
모바일 퍼스트 + PWA로 시작한다. Flutter 앱을 만들기 전에 PWA로 모바일 사용자를 먼저 확보할 수 있다.
dvh, safe area, 터치 타겟만 신경 쓰면 네이티브에 준하는 경험을 줄 수 있다.